百度飞桨·启航计划集训营(第四期)
前言
为期 8 周的 飞桨启航计划集训营(第四期) 即将进入尾声,笔者在这期 Paddle 开源活动中主要参与了两个方面的任务:
前期在使用 Docker 编译 Paddle 时,遇到了一些奇怪的问题:
这期启航计划的收获大致在三个方面:
1)AST IR 在 Expr、Stmt、Block 三层抽象下的读写机制(此外还有 function 和 module 两个层次);
2)CINN 后端 Pass 改造时的大致思路和注意点;
3)Git、PR, 与 Paddle CI 测试流程 的熟悉。
本文主要是从这三个方面对过去两个月在快乐飞桨的学习所得进行回顾和梳理,从一个小白的视角分享一些感悟,如有偏颇,恳请前辈们在评论区热心指点。
1. 处理的对象 —— AST IR
在 CINN 架构中,一个子图会分别经过 CINN 编译期的前端、后端进行变换。CINN 前端将输入的 PIR 变换后,输出为一组 FusionOp;CINN 后端则将这些 FusionOp 下降为更直观的 AST IR,再经过后端特有的编排调优 Schedule、代码生成和编译后,输出为 JitKernelOp;最后,该 JitKernelOp 会被运行期的执行器进行封装。
CINN 架构图
下面是一个简单的示例,展示了一个简单的计算图从前端到后端的转换过程。
1
2
3
4
5
# shape of x, y is [64, 128]
def forward ( self , x , y ):
tmp = x - y
out = tmp * x
return out
对于上面这张子图,其转换为 PIR 后的 Tensor 级别的 HIR 结构如下:
1
2
3
4
5
6
7
{
( % 0 ) = "pd_op.data" [ id : 18 ] () { dtype :( pd_op . DataType ) float32 , name : "x" , place :( pd_op . Place ) Place ( undefined : 0 ), shape :( pd_op . IntArray )[ 64 , 128 ], stop_gradient :[ false ]} : () -> builtin . tensor < 64 x128xf32 > { () } ( op_18 )
( % 1 ) = "pd_op.data" [ id : 19 ] () { dtype :( pd_op . DataType ) float32 , name : "y" , place :( pd_op . Place ) Place ( undefined : 0 ), shape :( pd_op . IntArray )[ 64 , 128 ], stop_gradient :[ false ]} : () -> builtin . tensor < 64 x128xf32 > { () } ( op_19 )
( % 2 ) = "pd_op.subtract" [ id : 20 ] ( % 0 , % 1 ) { stop_gradient :[ false ]} : ( builtin . tensor < 64 x128xf32 > , builtin . tensor < 64 x128xf32 > ) -> builtin . tensor < 64 x128xf32 > { () } ( op_20 )
( % 3 ) = "pd_op.multiply" [ id : 21 ] ( % 2 , % 0 ) { stop_gradient :[ false ]} : ( builtin . tensor < 64 x128xf32 > , builtin . tensor < 64 x128xf32 > ) -> builtin . tensor < 64 x128xf32 > { () } ( op_21 )
() = "builtin.shadow_output" [ id : 22 ] ( % 3 ) { output_name : "output_0" } : ( builtin . tensor < 64 x128xf32 > ) -> { } ( op_22 )
}
然后 CINN 前端将其转换为下面的 FusionOp:
1
2
3
4
5
6
7
8
9
10
11
{
( % 0 ) = "pd_op.data" [ id : 18 ] () { dtype :( pd_op . DataType ) float32 , name : "x" , place :( pd_op . Place ) Place ( undefined : 0 ), shape :( pd_op . IntArray )[ 64 , 128 ], stop_gradient :[ false ], sym_shape_str : "shape[64, 128], data[NULL]" } : () -> builtin . tensor < 64 x128xf32 > { ( shape [ 64 , 128 ], data [ NULL ]) } ( op_18 )
( % 1 ) = "pd_op.data" [ id : 19 ] () { dtype :( pd_op . DataType ) float32 , name : "y" , place :( pd_op . Place ) Place ( undefined : 0 ), shape :( pd_op . IntArray )[ 64 , 128 ], stop_gradient :[ false ], sym_shape_str : "shape[64, 128], data[NULL]" } : () -> builtin . tensor < 64 x128xf32 > { ( shape [ 64 , 128 ], data [ NULL ]) } ( op_19 )
( % 2 ) = "cinn_op.fusion" [ id : 29 ] () -> builtin . tensor < 64 x128xf32 > {
( % 3 ) = "pd_op.subtract" [ id : 26 ] ( % 0 , % 1 ) { stop_gradient :[ false ], sym_shape_str : "shape[64, 128], data[NULL]" } : ( builtin . tensor < 64 x128xf32 > , builtin . tensor < 64 x128xf32 > ) -> builtin . tensor < 64 x128xf32 > { ( shape [ 64 , 128 ], data [ NULL ]) } ( op_26 )
( % 4 ) = "pd_op.multiply" [ id : 27 ] ( % 3 , % 0 ) { stop_gradient :[ false ], sym_shape_str : "shape[64, 128], data[NULL]" } : ( builtin . tensor < 64 x128xf32 > , builtin . tensor < 64 x128xf32 > ) -> builtin . tensor < 64 x128xf32 > { ( shape [ 64 , 128 ], data [ NULL ]) } ( op_27 )
( % 5 ) = "cinn_op.yield_store" [ id : 28 ] ( % 4 ) {} : ( builtin . tensor < 64 x128xf32 > ) -> builtin . tensor < 64 x128xf32 > { ( shape [ 64 , 128 ], data [ NULL ]) } ( op_28 )
() = "cf.yield" [ id : 30 ] ( % 5 ) {} : ( builtin . tensor < 64 x128xf32 > ) -> { } ( op_30 )
} { ( shape [ 64 , 128 ], data [ NULL ]) } ( op_29 )
() = "builtin.shadow_output" [ id : 22 ] ( % 2 ) { output_name : "output_0" , sym_shape_str : "shape[64, 128], data[NULL]" } : ( builtin . tensor < 64 x128xf32 > ) -> { } ( op_22 )
}
在 CINN 后端,上面的 FusionOp 作为输入,将被下降到我们的处理对象 AST IR,其结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
ScheduleBlock ( root_1 )
{
serial for ( i , 0ll , 64ll )
{
serial for ( j , 0ll , 128ll )
{
ScheduleBlock ( var_3 )
{
i0_1 , i1_1 = axis . bind ( i , j ) // 用于调度的信息
var_3 [ i0_1 , i1_1 ] = (( var [ i0_1 , i1_1 ] - var_0 [ i0_1 , i1_1 ]) * var [ i0_1 , i1_1 ]) // 实际需要调度的语句
}
}
}
}
}
上述这段 AST IR 描述了 两个 shape 为 [64, 128] 的 Tensor 进行减后乘的运算,并在一个 ScheduleBlock 中对这个一轮运算进行调度。那么后端 Schedule 的任务就是对这段 AST IR 进行优化,使得其能够在硬件上高效运行。比如,将名称为 root_1 的 ScheduleBlock 调度到 32 个线程块、每个块运行 256 个线程,来实现对上述运算的高度并行化。经过 Schedule 编排后的 AST IR 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
{
ScheduleBlock ( root_1 )
{
thread_bind [ blockIdx . x ] for ( i_j_fused , 0 , 32 )
{
thread_bind [ threadIdx . x ] for ( i_j_fused_0 , 0 , 256 )
{
ScheduleBlock ( var_3 )
{
// 用于调度的 iter_vars, iter_values
i0_1 , i1_1 = axis . bind (((( i_j_fused * 256 ) + i_j_fused_0 ) / 128 ), ( i_j_fused_0 % 128ll ))
// 用于调度的 read_buffers
read_buffers ( _var [ i0_1 ( 0 : 64ll ), i1_1 ( 0 : 128ll )], _var_0 [ i0_1 ( 0 : 64ll ), i1_1 ( 0 : 128ll )], _var [ i0_1 ( 0 : 64ll ), i1_1 ( 0 : 128ll )])
// 用于调度的 write_buffers
write_buffers ( _var_3 [ i0_1 ( 0 : 64ll ), i1_1 ( 0 : 128ll )])
// 实际需要调度的语句(body)
var_3 [ i0_1 , i1_1 ] = (( var [ i0_1 , i1_1 ] - var_0 [ i0_1 , i1_1 ]) * var [ i0_1 , i1_1 ])
}
}
}
}
}
2. IR 节点的遍历
假设现在有下面一段 IR,我们需要精简其中的 For 语句(若 trip_count==1 ,那么这个 For 语句只需保留其 body,并替换循环体的迭代遍量为 min 表达式)、以及可以简化的立即数运算(比如 0 + 0)。
注: 下面的 IR 节点为新 IR 下 stmt 的命名 。
1
2
3
4
5
6
7
8
9
10
11
{
serial for ( i_k_a_fused , 1ll , 2ll ) {
Schedule ( var_45 ) {
i0_94 , i1_77 , i2_77 , i3_67 = axis . bind (( i_k_a_fused / 100ll ), ( append_var_13_j_append_var_14_append_var_15_fused % 10ll ), (( i_k_a_fused % 100ll ) / 10ll ), ( i_k_a_fused % 10ll ))
read_buffers (...)
write_buffers (...)
var_45 [ i0_94 , i1_77 , i2_77 , i3_67 ] =
( float16 (( var_4 [ i0_94 , i1_77 , i2_77 , i3_67 ] > ( float16 ) 0.0000f )) * float16 ((( var_16 [ i1_77 ] * var_9 [ i1_77 ]) * (( float32 (( var [ 0 ] / ( float16 ) 4000.0f )) - ( var_11 [ 0 , i1_77 , 0 , 0 ] / 400.000000f )) - (( float32 ( var_4 [ i0_94 , i1_77 , i2_77 , i3_67 ]) - var_7 [ i1_77 ]) * ((( var_15 [ 0 , i1_77 , 0 + 0 , 0 + 0 ] / 400.000000f ) * var_9 [ i1_77 ]) * var_9 [ i1_77 ]))))))
}
}
}
我们期望的简化结果是:
1
2
3
4
5
6
7
8
{
Schedule ( var_45 ) {
i0_94 , i1_77 , i2_77 , i3_67 = axis . bind (( 1 / 100ll ), ( append_var_13_j_append_var_14_append_var_15_fused % 10ll ), ( 1 % 100ll ) / 10ll ), ( 1 % 10ll ))
read_buffers (...)
write_buffers (...)
var_45 [ i0_94 , i1_77 , i2_77 , i3_67 ] = ( float16 (( var_4 [ i0_94 , i1_77 , i2_77 , i3_67 ] > ( float16 ) 0.0000f )) * float16 ((( var_16 [ i1_77 ] * var_9 [ i1_77 ]) * (( float32 (( var [ 0 ] / ( float16 ) 4000.0f )) - ( var_11 [ 0 , i1_77 , 0 , 0 ] / 400.000000f )) - (( float32 ( var_4 [ i0_94 , i1_77 , i2_77 , i3_67 ]) - var_7 [ i1_77 ]) * ((( var_15 [ 0 , i1_77 , 0 , 0 ] / 400.000000f ) * var_9 [ i1_77 ]) * var_9 [ i1_77 ]))))))
}
}
在未简化的 IR 中,含有两个基本结构:For Expr 和 Schedule(ScheduleBlock) Expr 。其中 For 语句用于描述循环结构,Schedule 语句用于描述调度信息。For 语句的 iter_var(循环迭代遍历), min(循环起始值), extent(循环边界) 表达式需要我们去访问,从而确定这个 For 语句是否可以被简化。而 Schedule 语句则作为 For 语句的 body,负责调度运算任务。
在写这样的 Pass 前,我们需要考虑以下几个问题:
1)如何对这个 IR 进行遍历?
2)遍历时需考虑新旧 IR 的哪些区别?
3)应该从新 IR 的哪个层次进行实现,如何确认这一点?
4)如何测试改造后 Pass 的正确性?
2.1 利用 IRMutator 进行遍历
为了简化上述 IR,我们不得不对上述 IR 中不同层次的语句和表达式进行遍历。对于问题 1),在改造 CINN 后端 Pass 前,我们是通过 IRMutator 对语句进行遍历的,IRMutator 的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
//! T might be Expr* or const Expr*
template < typename T = Expr *>
class IRMutator : public IRVisitorRequireReImpl < void , T > {
public :
void Visit ( const Expr * expr , T op ) override ;
virtual void Visit ( _Module_ * op );
virtual void Visit ( _LoweredFunc_ * op );
#define __(op__) void Visit(const op__ *op, T expr) override;
NODETY_FORALL ( __ )
#undef __
};
其中,基类的 Visit 函数被用作遍历 IR 中的节点,每个类型的语句在 IRMutator 基类中均有默认的实现,下面是 IRMutator 中对 For 语句的遍历实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
// Definition of For Expr
struct For : public ExprNode < For > , public ForBase {
//! The loop variable.
Var loop_var ;
//! The minimum value of the iteration.
Expr min ;
//! The extent of the iteration.
Expr extent ;
Expr body ;
DeviceAPI device_api ;
LLVMForLoopMeta metadata ;
static Expr Make ( Var loop_var ,
Expr min ,
Expr extent ,
ForType for_type ,
DeviceAPI device_api ,
Expr body ,
VectorizeInfo vector_info = VectorizeInfo (),
BindInfo bind_info = BindInfo ());
void Verify () const override ;
std :: vector < Expr *> expr_fields () override ;
std :: vector < const Expr *> expr_fields () const override ;
static const IrNodeTy _node_type_ = IrNodeTy :: For ;
};
// ...
// ...
template < typename T >
void IRMutator < T >:: Visit ( const For * expr , T op ) {
auto * node = op -> template As < For > ();
IRVisitorRequireReImpl < void , T >:: Visit ( & node -> min , & node -> min );
IRVisitorRequireReImpl < void , T >:: Visit ( & node -> extent , & node -> extent );
IRVisitorRequireReImpl < void , T >:: Visit ( & node -> body , & node -> body );
}
默认实现的 Visit 函数会对 For 语句的 min, extent, body 三个部分进行遍历,我们可以通过继承 IRMutator 并重载 Visit 函数来实现对 For 语句的特殊遍历。
2.2 利用 StmtMutator/StmtVisitor 进行遍历
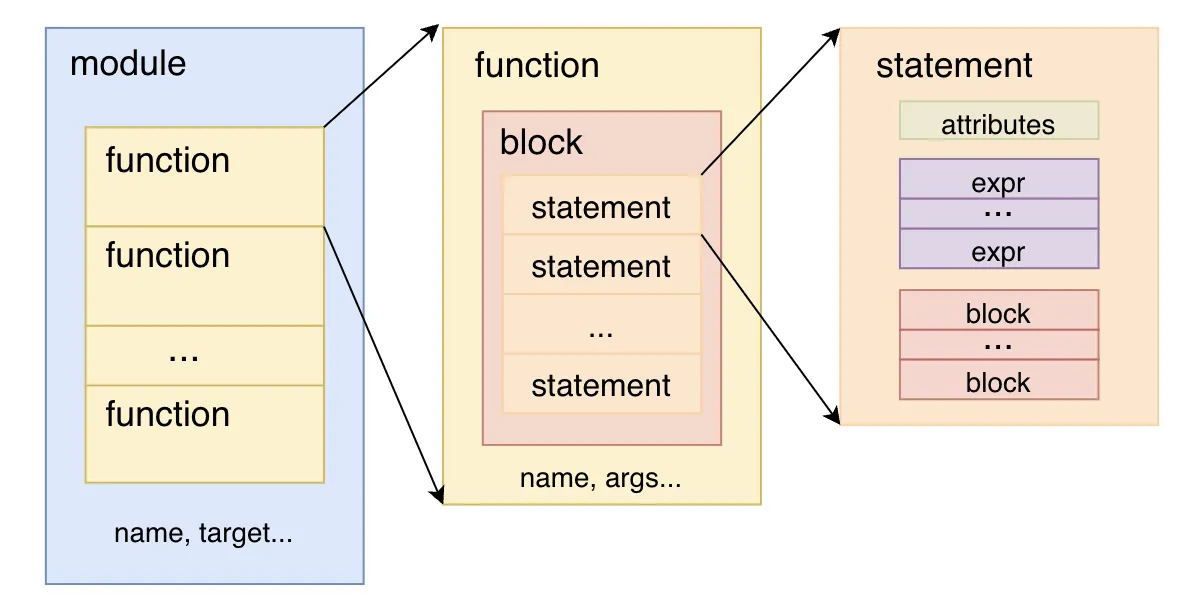
对于问题 2),在新的后端 Pass 中,CINN 对 IR 进行了更高层次的 5 个级别的抽象: expr、statmemt、block、function,和 module。
IR 抽象层次
与之对应的,CINN 也提供了新的语句遍历类 StmtMutator 和 StmtVisitor,其中 StmtMutator 用于对 IR 进行读写,而 StmtVisitor 仅对 IR 进行只读访问。下面以 StmtMutator 读写遍历类为例,简述其工作原理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
template < typename StmtRetTy = void ,
typename BlockRetTy = void ,
typename ... Args >
class StmtMutator {
public :
virtual StmtRetTy VisitStmt ( StmtRef stmt , Args ... args ) {
CINN_CHECK_STMT_DEFINED ( stmt )
switch ( stmt -> stmt_type ()) {
#define __(stmt__) \
case ir::StmtNodeTy::stmt__: \
return VisitStmt(stmt.as<stmt__>(), args...); \
break;
NODETY_FORALL_STMT ( __ )
default :
PADDLE_THROW ( :: common :: errors :: InvalidArgument (
"Deadcode, not supported StmtNodeTy" ));
#undef __
}
}
// Default implementation for visiting block with void return type.
virtual BlockRetTy VisitBlock ( BlockRef block , Args ... args ) {
std :: vector < StmtRef > new_stmts = block -> stmts ();
for ( StmtRef inner_stmt : new_stmts ) {
VisitStmt ( inner_stmt );
}
block -> set_stmts ( new_stmts );
return BlockRetTy ();
}
protected :
#define __(stmt__) virtual StmtRetTy VisitStmt(stmt__ stmt, Args... args) = 0;
NODETY_FORALL_STMT ( __ )
#undef __
};
基类 class StmtMutator 暴露了 2 个公有函数:VisitStmt(const StmtRef &stmt, Args... args) 和 VisitBlock(const BlockRef &block, Args… args)。其中,基类默认实现的 VisitBlock() 函数用于对当前层级 Block 中的语句进行遍历。当我们要继承 class StmtMutator 对某 IR 进行特殊需求的遍历时,可以复用该虚函数。而公有函数 VisitStmt() 则负责将不同类型的语句(StmtRef 的各种子类语句)进行分发到对应的私有纯虚函数 VisitStmt() 进行语句遍历。
上述提到的一系列私有纯虚函数 VisitStmt(),具体包括对以下语句(节点)的 访问:
1
2
3
4
5
6
7
8
class Let ;
class Store ;
class Alloc ;
class Free ;
class IfThenElse ;
class For ;
class Evaluate ;
class Schedule ;
在写 Pass 继承 StmtMutator 时,我们只需重载这些私有纯虚函数,自定义每个语句的遍历逻辑即可。可以看到,在继承新 IR 下的遍历类 StmtMutator时,需要我们重写基类的所有纯虚函数 VisitStmt(),而旧 IR 下的 IRMutator 则只需要重写与 Pass 功能有关的 Visit 函数即可。该方式本身的问题是许多情况下我们并不需要对所有语句或者表达式都进行遍历,而只关注某些特定的语句进行重写,那么 IRMutator 默认实现的各种 Visit 函数就变得冗余。新 IR 下的 StmtMutator 在重写 VisitStmt() 时,可以进行手动截断,从而避免不必要的遍历。不过只通过继承 StmtMutator 来遍历 IR 也会带来新的问题:对于原本使用 IRMutator 的只需要重写某种语句(比如 Store)的 Pass,在新 IR 下继承 StmtMutator 后,需要重写所有语句的遍历函数(尽管可以直接截断),并且需要考虑所有可能含有 Store 语句的 VisitStmt() 的实现。对于这种情况,我们也可以无需继承 StmtMutator 类,而只需手动实现某个 Visit 方法负责分析变换,将遍历语句的任务转交给下面的 PassManager 管理类即可。
3. Pass 管理类 PassManager
新 IR 中,CINN 提供了一个 PassManager 类,用于管理 Pass 的注册和执行,其分别对四个级别的 Pass 进行管理:ExprPass、StmtPass、BlockPass 和 FuncPass。PassManager 提供 3 个公有函数:AddPass(std::unique_ptr<PassT> pass),Run(ir::LoweredFunc func) 和 Run(ir::stmt::BlockRef block),分别负责向 PassManager 中添加 Pass,利用指定级别的 PassAdapter 对函数或 Block 执行 Pass。
下面是 PassManager 的定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
namespace cinn {
namespace optim {
template < typename PassT , typename PassAdaptorT >
class PassManager {
public :
virtual LogicalResult Run ( ir :: LoweredFunc func ) {
return adaptor_ . RunPipeline ( func , passes_ );
}
virtual LogicalResult Run ( ir :: stmt :: BlockRef block ) {
return adaptor_ . RunPipeline ( block , passes_ );
}
void AddPass ( std :: unique_ptr < PassT > pass ) {
passes_ . emplace_back ( std :: move ( pass ));
}
private :
std :: vector < std :: unique_ptr < PassT >> passes_ ;
PassAdaptorT adaptor_ ;
};
using FuncPassManager = PassManager < FuncPass , detail :: FuncPassAdaptor > ;
using BlockPassManager = PassManager < BlockPass , detail :: BlockPassAdaptor > ;
using StmtPassManager = PassManager < StmtPass , detail :: StmtPassAdaptor > ;
using ExprPassManager = PassManager < ExprPass , detail :: ExprPassAdaptor > ;
} // namespace optim
} // namespace cinn
以 class BlockPassManager 为例,其适配器 BlockPassAdaptor 的 Run() 函数对要应用 Pass 的 Block 进行 DFS 遍历。在遍历过程中,对于当前 Block 的每个 Stmt,递归遍历其内部的 Block,直至遍历到最底层的 Stmt,然后对这个 Stmt 应用 Pass。因此如果我们要如果在 Block 级别对 IR 进行变换,使用 BlockPass 时就需保证:对于输入的 Block,其内部最内层的 Block 也能包含变换所需的信息。
下面是 class BlockPassAdaptor 的定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// BlockPassManager
using BlockPassManager = PassManager < BlockPass , detail :: BlockPassAdaptor > ;
class BlockPassAdaptor : public PassAdaptor < BlockPass > {
private :
LogicalResult Run (
ir :: LoweredFunc func ,
const std :: vector < std :: unique_ptr < BlockPass >>& passes ) override ;
LogicalResult Run (
ir :: stmt :: BlockRef block ,
const std :: vector < std :: unique_ptr < BlockPass >>& passes ) override ;
};
// implementation of Run() of BlockPassAdaptor
LogicalResult BlockPassAdaptor :: Run (
ir :: stmt :: BlockRef block ,
const std :: vector < std :: unique_ptr < BlockPass >>& passes ) {
std :: vector < ir :: stmt :: StmtRef > new_stmts = block -> stmts ();
for ( ir :: stmt :: StmtRef inner_stmt : new_stmts ) {
std :: vector < ir :: stmt :: BlockRef > inner_blocks = inner_stmt -> block_fields ();
for ( ir :: stmt :: BlockRef inner_block : inner_blocks ) {
if ( Run ( inner_block , passes ). failed ()) return LogicalResult :: failure ();
}
inner_stmt -> set_block_fields ( inner_blocks );
}
block -> set_stmts ( new_stmts );
return RunPasses ( passes , block );
}
那么对于问题 3),我们可以按如下规则评估实现为何种级别的 Pass:
ExprPass :所需变换信息仅局限于语句、表达式、不含 Block 的语句;StmtPass :不依赖 Stmt 在其所在 Block 上下文信息的变换(比如替换、删除当前 stmt 的变化则要高于本级别);BlockPass :所需变换信息全部可在 Block 内部获得,无需 Block 的父亲信息的;FuncPass :所需变换信息依赖于函数的上下文信息。
4. 测试 Pass 的正确性
后端 Pass 改造的任务的 Pass 验证主要在本地对关键 unittest 进行测试,然后利用 Paddle CI 跑多项完整测试。
4.1 本地测试
这里设计 Google Test 的部分参数使用(如 GLOG_v),pytest,ctest 等。
我是利用 Makefile 将几种工具综合在一起使用的,包括了 paddle 的编译,单测,清理等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# Define variables
BUILD_DIR = build
DATETIME = $( shell date +'%Y-%m-%d_%H:%M:%S' )
CMAKE_FLAGS = -DPY_VERSION= 3.10 \
= ON \
= ON \
= ON \
= OFF
# Generate CMake files
config :
ifeq ( $( wildcard $( BUILD_DIR )) ,)
$( shell mkdir $( BUILD_DIR ))
endif
cd $( BUILD_DIR ) && cmake .. $( CMAKE_FLAGS ) 2>&1 | tee cmake_ $( DATETIME ) .log
.PHONY : config build clean rt rtd
# Build the project
build :
cd $( BUILD_DIR) && make -j96 2>& 1 | tee build_$( DATETIME) .log
rt :
cd $( BUILD_DIR) && ctest -R test_cinn_* | tee ctest_$( DATETIME) .log
rtd :
cd $( BUILD_DIR) && GLOG_v = 6 ctest -R test_cinn_* -VV | tee ctest_$( DATETIME) .log
# all
all : config build
echo "Build all finished"
# Clean the build directory
clean :
rm -rf $( BUILD_DIR)
在验证 Pass 的某个局部代码的正确性时,往往我们在其上下文打印 log,不过有些 case 的测试时间较长,等待 log 输出会比较慢。这里我们可以通过手动抛出异常来快速中断测试,然后通过 GLOG_v 等参数来控制 log 输出的详细程度。
比如在测试 FooPass 的 VisitStmt(Store, ...) 函数时,加入如下手动中断:
1
2
3
4
5
6
7
8
9
10
11
12
13
class FooPass : public ir :: stmt :: StmtMutator {
public :
void VisitStmt ( const ir :: stmt :: Store stmt ) override {
LOG ( INFO ) << "Visit Store" ;
if ( condition ) {
// ...
// ...
// LOG(INFO) << "Find Store";
PADDLE_THROW ( :: common :: errors :: InvalidArgument ( "Find Store: %s" , stmt -> name ()));
}
}
};
4.2 PR-CE-CINN-Freamework CI 的本地复现
1
2
3
4
5
6
7
8
9
export FLAGS_prim_all = True # 开启组合算子策略
export FLAGS_prim_enable_dynamic = true #组合算子允许动态Shape
export FLAGS_print_ir = 1 # 会打印日志,供RD调试
export FLAGS_enable_pir_api = 1 # 会开启新IR
export FLAGS_cinn_new_group_scheduler = 1
export FLAGS_group_schedule_tiling_first = 1
export FLAGS_cinn_bucket_compile = 1
export FRAMEWORK = paddle # 设置FRAMEWORK,paddle/torch
export PLT_SET_DEVICE = "gpu" # gpu/cpu
1
2
3
4
5
6
7
8
if __name__ == "__main__" :
layerfile = "layercase/sublayer1000/Det_cases/ppyoloe_voc_ppyoloe_plus_crn_s_30e_voc/SIR_179.py"
testing = "yaml/CI_dy^dy2stcinn_train^dy2stcinn_eval_inputspec.yml"
# testing = "yaml/dy_eval.yml"
# testing = "yaml/dy_train.yml"
single_test = LayerTest ( title = layerfile , layerfile = layerfile , testing = testing )
single_test . _case_run ()
exit ( 0 )
测试:运行 python layertest.py
后记
参与飞桨启航计划集训营的初衷是为了熟悉 Compiler 后端在 IR 中具体的事情,希望自己面对这个领域能够从 “是什么” 过渡到 “为什么”,从而帮助我在科研上的新方向快速上手。
在改造 CINN 后端 Pass 的过程中,非常感谢 mentor —— CHQ 师傅的耐心指导,她对我产生的疑惑和错误都十分包容,并予以了详细解答。同时也感谢老朋友周鑫与我长期保持的交流。A good friend is a good teacher.
参考资料
 Albresky's Blog
Albresky's Blog
 支付宝
支付宝
 微信
微信
