 Albresky's Blog
Albresky's Blog
聚类任务总结
K-Means、学习向量化、高斯混合聚类、密度聚类、层次聚类
1 性能度量
性能度量是用来衡量一个聚类结果的好坏的概念。
1.1 外部指标
1.1.1 Jaccard系数(Jaccard Coefficient, JC)
$$ J C=\frac{a}{a+b+c} $$
1.1.2 FM指数(Fowlkes and Mallows Index, FMI)
$$ F M I=\sqrt{\frac{a}{a+b} \cdot \frac{a}{a+c}} $$
1.1.3 Rand指数(Rand Index, RI)
$$ R I=\frac{2(a+d)}{m(m-1)} $$
其中,m表示簇的数目。
1.1.4 隶属度
$$ \left.a=|S S|, \quad S S=\left{\left( x {i}, x {j}\right) \mid \lambda{i}=\lambda{j}, \lambda_{i}^{}=\lambda_{j}^{}, i<j\right)\right} $$
$$ \left.b=|S D|, \quad S D=\left{\left( x {i}, x {j}\right) \mid \lambda{i}=\lambda{j}, \lambda_{i}^{} \neq \lambda_{j}^{}, i<j\right)\right} $$
$$ \left.c=|D S|, \quad D S=\left{\left( x {i}, x {j}\right) \mid \lambda{i} \neq \lambda{j}, \lambda_{i}^{}=\lambda_{j}^{}, i<j\right)\right} $$
$$ \left.d=|D D|, \quad D D=\left{\left( x {i}, x {j}\right) \mid \lambda{i} \neq \lambda{j}, \lambda_{i}^{} \neq \lambda_{j}^{}, i<j\right)\right} $$
S表示Same,D表示Different。
SS表示,对于某两个样本,我们的聚类结果和外部指标相比,都判定为同一簇;同理,SD表示,对于某两个样本,我们的聚类结果将样本划到相同簇,而外部指标将其划分为不同的簇。
1.2 内部指标
1.2.1 簇内样本的平均距离
$$ \operatorname{avg}(C)=\frac{2}{|C|(|C|-1)} \sum_{1 \leqslant i<j \leqslant|C|} \operatorname{dist}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right) $$
求和符号前即为任意两个样本的排列数的倒数,故avg(C)表示,求两个簇样本之间的平均距离。
1.2.2 簇内样本的最大距离
$$ \operatorname{diam}(C)=\max {1 \leqslant i<j \leqslant|C|} \operatorname{dist}\left(\boldsymbol{x}{i}, \boldsymbol{x}_{j}\right) $$
1.2.3 簇间样本的最小距离
$$ d_{\min }\left(C_{i}, C_{j}\right)=\min {\boldsymbol{x}{i} \in C_{i}, \boldsymbol{x}{j} \in C{j}} \operatorname{dist}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right) $$
1.2.4 簇中心间的距离
$$ d_{\text {cen }}\left(C_{i}, C_{j}\right)=\operatorname{dist}\left(\mu_{i}, \mu_{j}\right) $$
其中,$\mu_{i}$表示第i个簇的中心。
1.2.5 DB指数
- DB 指数(Davies-Bouldin Index, 简称 DBI)
$$ \mathrm{DBI}=\frac{1}{k} \sum_{i=1}^{k} \max {j \neq i}\left(\frac{\operatorname{avg}\left(C{i}\right)+\operatorname{avg}\left(C_{j}\right)}{d_{\mathrm{cen}}\left(\boldsymbol{\mu}{i}, \boldsymbol{\mu}{j}\right)}\right) $$
其中,分子表示簇内样本的平均距离,分母表示簇间距离。因此,分子越小,分母越大,那么两个簇之间的距离就越大,因此DB指数越小,聚类效果越好。
1.2.6 Dunn指数
- Dunn 指数 (Dunn Index, 简称 DI)
$$ \mathrm{DI}=\min {1 \leqslant i \leqslant k}\left{\min {j \neq i}\left(\frac{d{\min }\left(C{i}, C_{j}\right)}{\max {1 \leqslant l \leqslant k} \operatorname{diam}\left(C{l}\right)}\right)\right} $$
其中,分子表示求簇间样本的最小距离,分母表示求簇内样本的最大距离。因此,若簇间样本的最小距离都很大,簇内样本的最大距离都很小,且它们的比值的最小值都很大时,即DB的最下值都很大时,聚类效果就会越好。
2 距离计算
样本间的距离如何确定?
2.1 距离度量/非距离度量
2.1.1 距离度量
若样本间符合距离度量,那么它们之间必须满足以下条件:
- 非负性: $\operatorname{dist}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right) \geqslant 0$
- 同一性: $\operatorname{dist}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right)=0$ 当且仅当 $\boldsymbol{x}{i}=\boldsymbol{x}{j}$
- 对称性: $\operatorname{dist}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right)=\operatorname{dist}\left(\boldsymbol{x}{j}, \boldsymbol{x}{i}\right)$
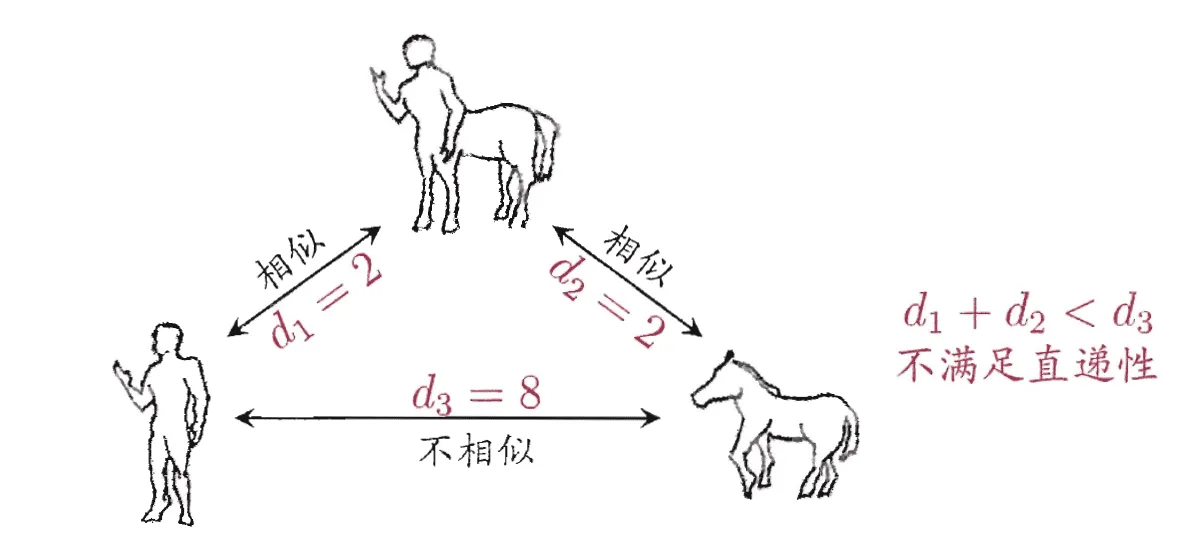
- 直递性: $\operatorname{dist}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right) \leqslant \operatorname{dist}\left(\boldsymbol{x}{i}, \boldsymbol{x}{k}\right)+\operatorname{dist}\left(\boldsymbol{x}{k}, \boldsymbol{x}{j}\right)$
上述关系很直观,就不赘述。
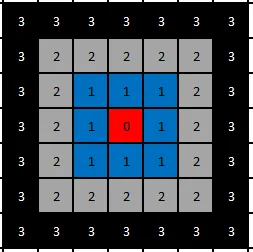
2.1.2 非距离度量
K-Means西瓜书上很形象的一幅非距离度量的图。
2.2 有序属性/无序属性
2.2.1 有序属性
- 闵可夫斯基距离
$$ \operatorname{dist}{\mathrm{mk}}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right)=\left(\sum{u=1}^{n}\left|x_{i u}-x_{j u}\right|^{p}\right)^{\frac{1}{p}} $$
当p=2时,闵可夫斯基距离即为欧氏距离:
- 欧氏距离
$$ \operatorname{dist}{e d}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right)=\left|\boldsymbol{x}{i}-\boldsymbol{x}{j}\right|{2}=\sqrt{\sum_{u=1}^{n}\left|x_{i u}-x_{j u}\right|^{2}} $$
其中,$\left|x_{i}-x_{j}\right|_{2}$ 为$\text { norm - L2 }$ 范数。
当p=1,时,闵可夫斯基距离即为曼哈顿距离:
- 曼哈顿距离
$$ \operatorname{dist}{\operatorname{man}}\left(\boldsymbol{x}{i}, \boldsymbol{x}{j}\right)=\left|\boldsymbol{x}{i}-\boldsymbol{x}{j}\right|{1}=\sum_{u=1}^{n}\left|x_{i u}-x_{j u}\right| $$
其中,$\left|x_{i}-x_{j}\right|_{1}$ 为$\text { norm - L1 }$ 范数。

曼哈顿距离上图中,绿线为欧氏距离,蓝线、黄线、红线均为曼哈顿距离。
- 切比雪夫距离
切比雪夫距离3 原型聚类
3.1 K-Means聚类(K均值算法)
-
效果:

K-Means -
步骤
- 随机选取k个中心点(质点),即k个簇;
- 分别计算所有样本到中心点的距离,若距离第i个中心点最近,那么该样本隶属第i个簇;
- 重复上一步,直至上一步收敛。
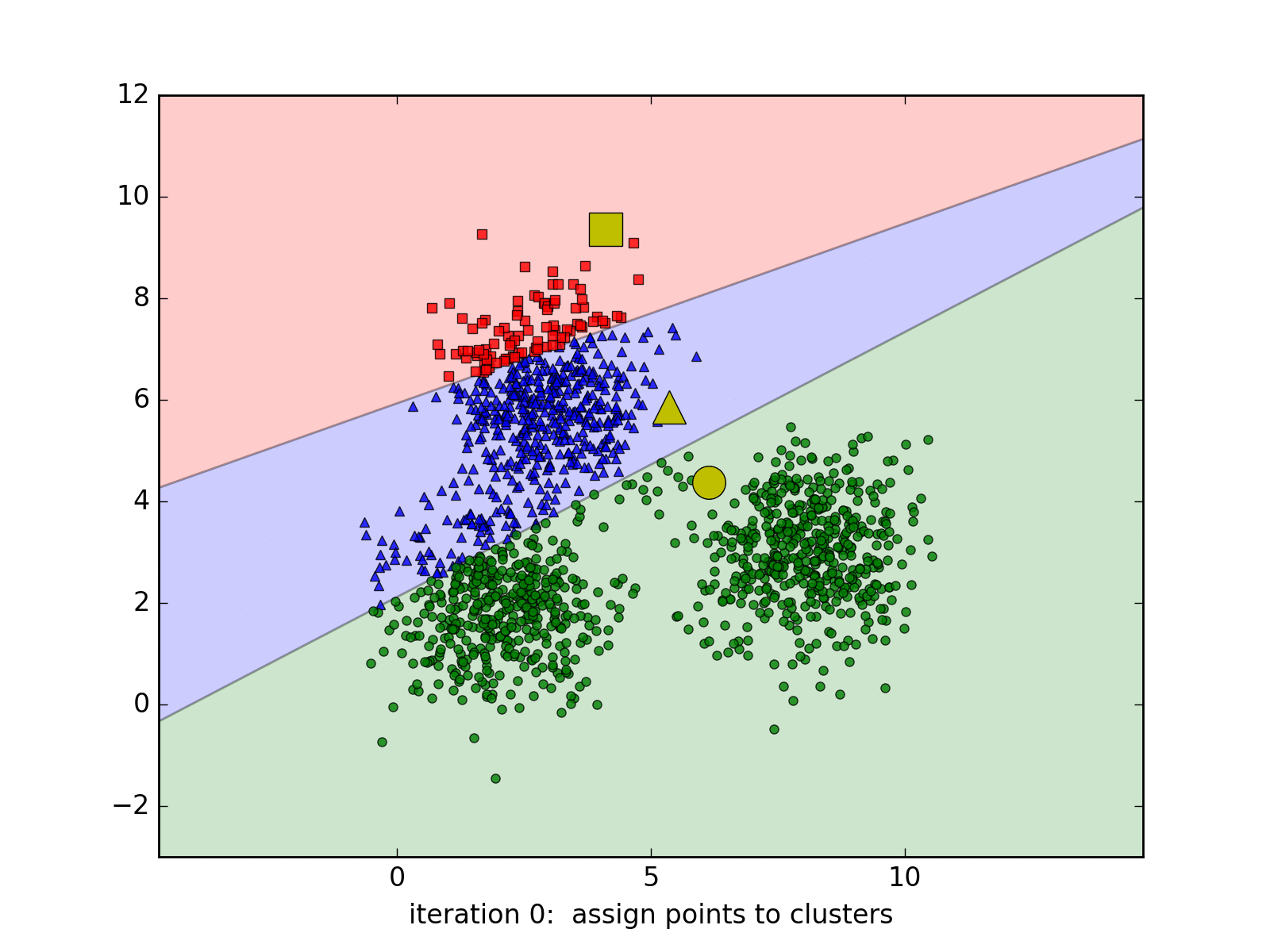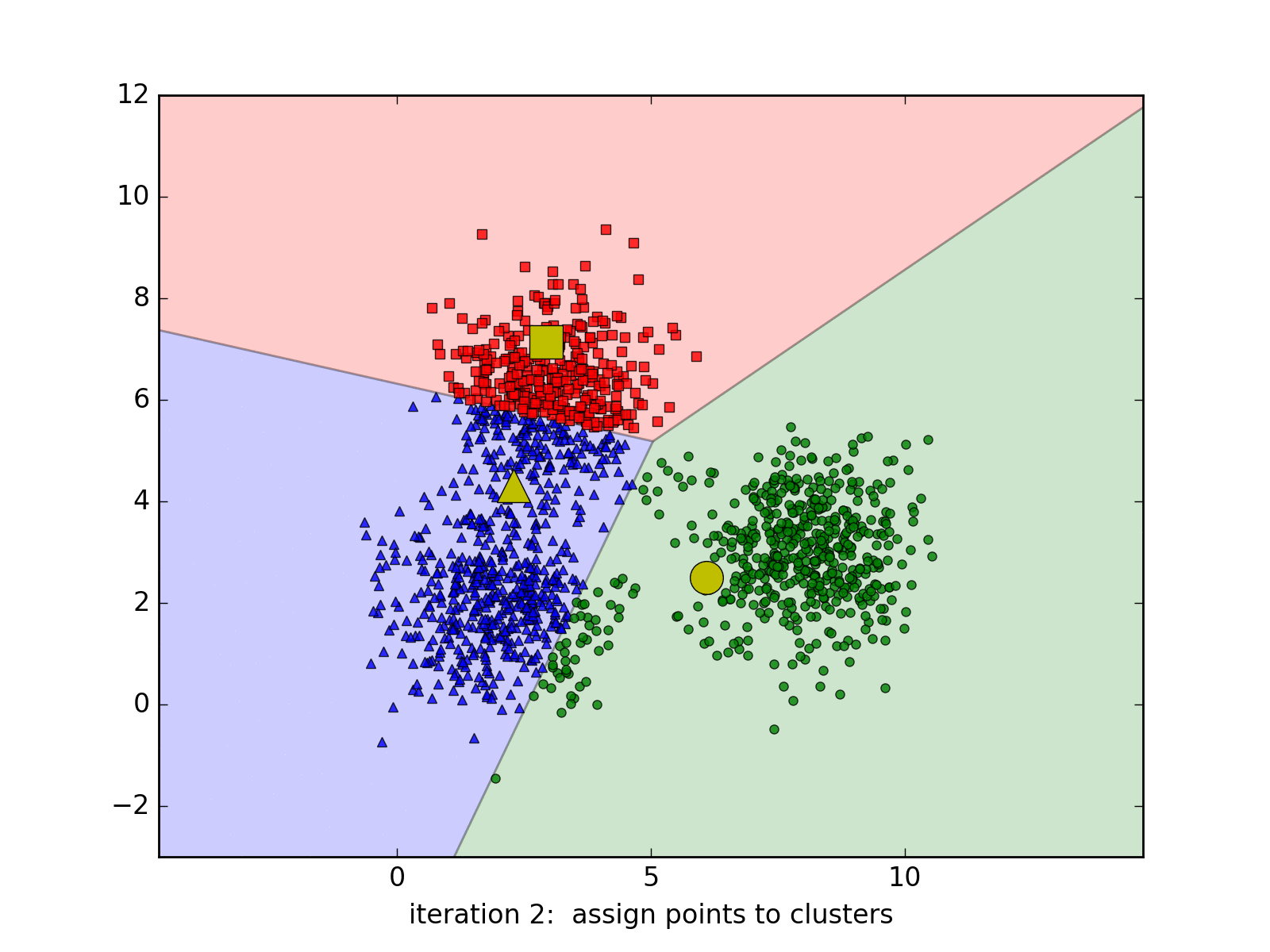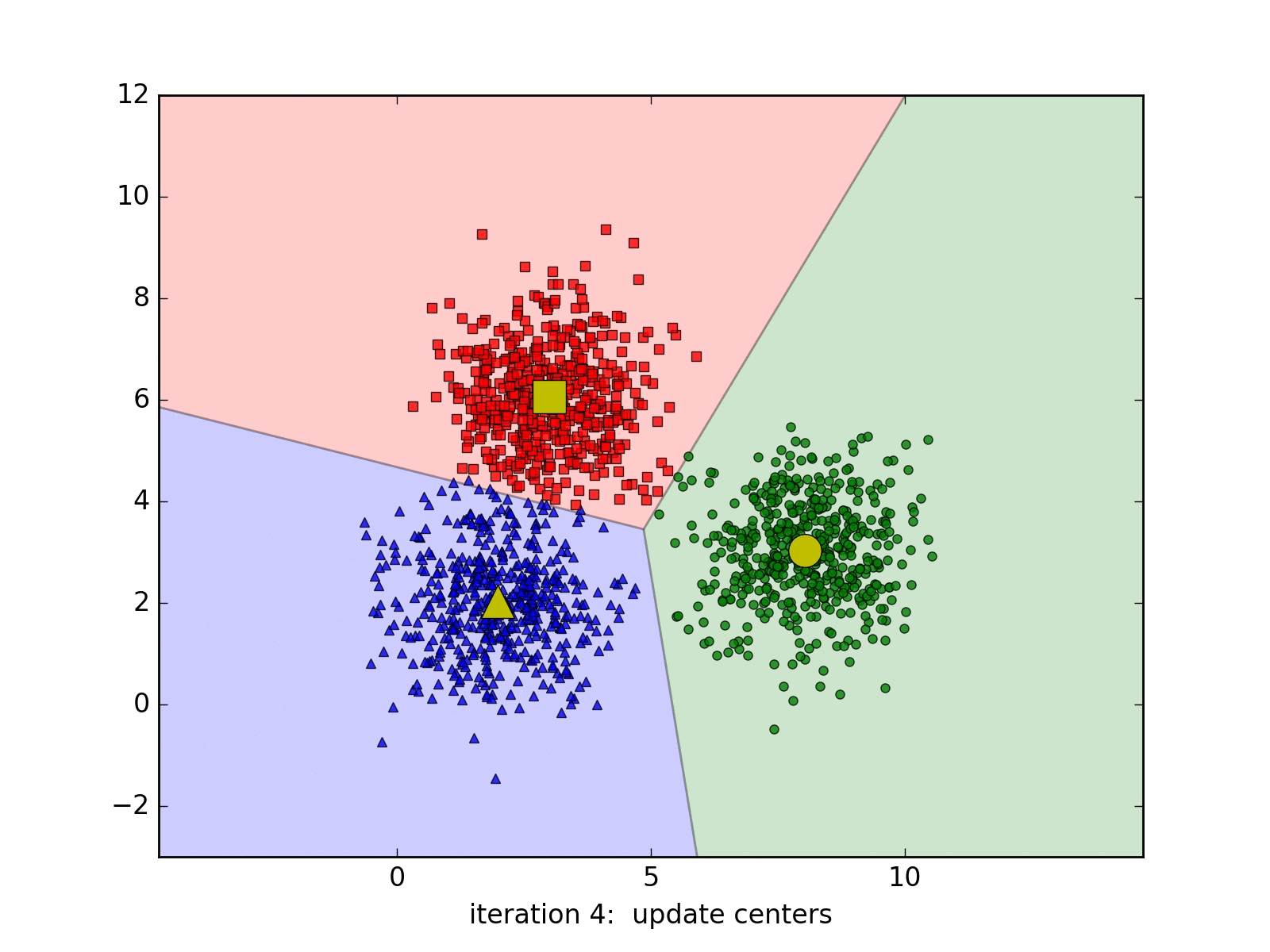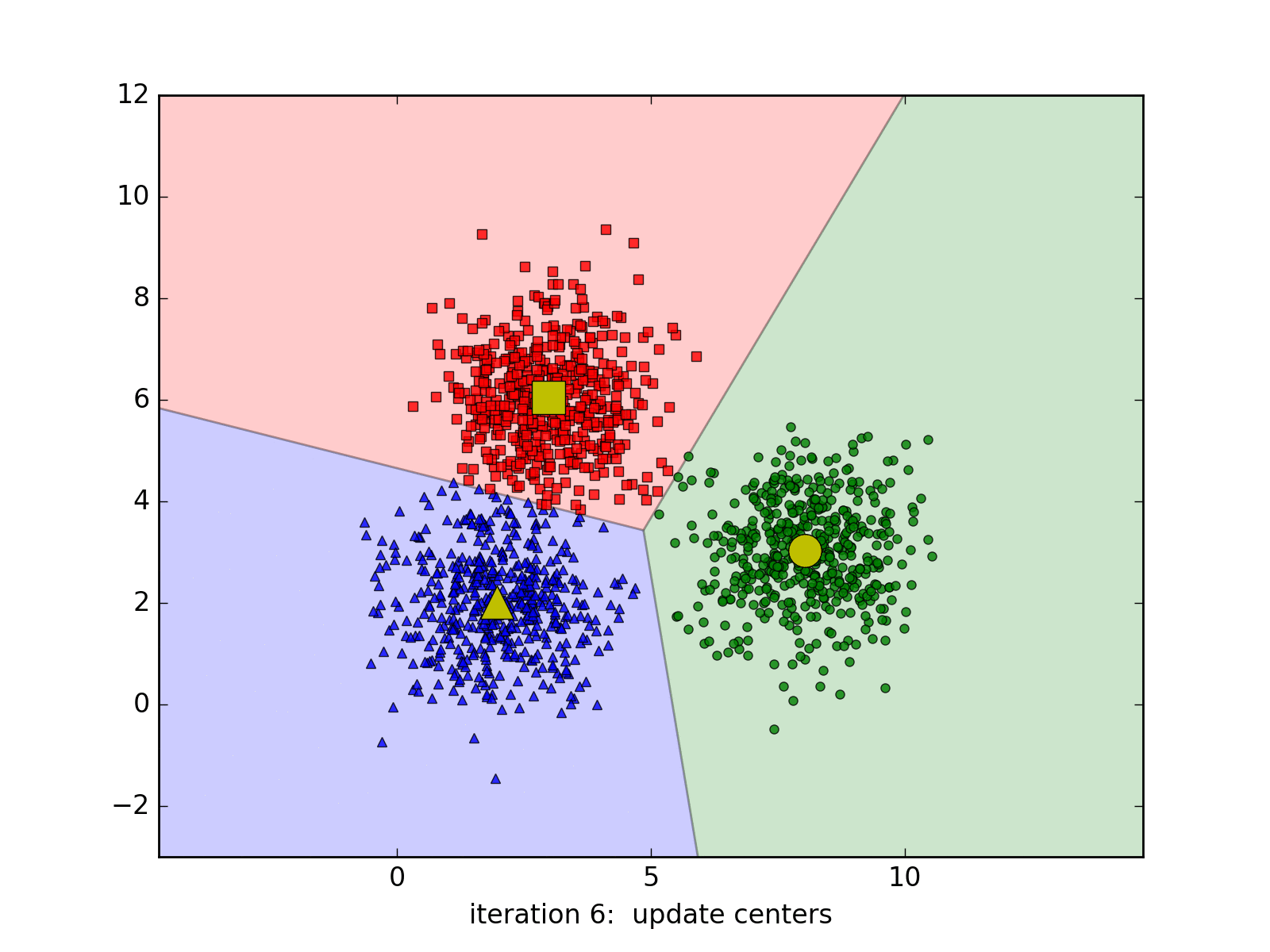
3.2 LVQ学习向量量化
和K-Means的不同:
- 每个样本都有标签,即LVQ是监督式学习;
- LVQ并不像K-Means输出簇的划分,而是输出每个类的原型向量;
3.2.1 步骤
- 初始化给定一组原型向量;
- 分别计算离每个原型向量a最近的样本s;
- 若该样本s与原型向量a隶属同一类别,那么$\boldsymbol{p}^{\prime}=\boldsymbol{p}{i^{*}}+\eta \cdot\left(\boldsymbol{x}{j}-\boldsymbol{p}{i^{*}}\right)$
;否则$\boldsymbol{p}^{\prime}=\boldsymbol{p}{i^{}}-\eta \cdot\left(\boldsymbol{x}{j}-\boldsymbol{p}{i^{}}\right)$; - 重复上面两步,直至其收敛。
 支付宝
支付宝
 微信
微信
