CUTLASS 4.2.0 ———— 深入浅出 CuTe DSL 与 CuTe C++
TMA: CuTe DSL V.S. CuTe C++
总结: CuTe C++ 高度依赖模板函数的特化,本质是将 PTX 内敛汇编 封装成模板函数,通过模板参数特化到不同的 TMA 指令;而 CuTe DSL 利用抽象出来的 cute dialect (包含 cutlass_gpu, cute_nvgpu等)逐步 lower 抽象,从 cute_nvgpu –> nvvm/scf/arith –> llvm,最后利用 llvm ir 生成 CUBIN(SASS),其中 JIT_executor 可以在 runtime 为 gpu_binary 设置动态 tensor shape。
本文以 cp.async 指令(cutlass/blob/main/examples/python/CuTeDSL/blackwell/dense_gemm.py#L1804) 为例,对比 CuTeDSL Python 和 CuTe C++ 的路径。
例程
examples/python/CuTeDSL/blackwell/dense_gemm.py
包含指令:
CuTe DSL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Python DSL Code
↓
cute.jit (遍历装饰器修饰的func)
↓
cute.compile (JIT 入口)
↓
MLIR IR (多层 Dialect)
↓
LLVM IR (含内联 PTX)
↓
PTX ASM
↓
.CUBIN
↓
GPU Execution
|
1. 引入封装的cpasync
1
|
from cutlass.cute.nvgpu import cpasync
|
2. 在 @cute.jit host 侧装饰的 __call__方法
(examples/python/CuTeDSL/blackwell/dense_gemm.py#L414)中,创建 store 指令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
@cute.jit
def __call__(
self,
a: cute.Tensor,
b: cute.Tensor,
c: cute.Tensor,
stream: cuda.CUstream,
epilogue_op: cutlass.Constexpr = lambda x: x,
):
# Setup store for C
tma_atom_c = None
tma_tensor_c = None
if cutlass.const_expr(self.use_tma_store):
c_cta_v_layout = cute.composition(
cute.make_identity_layout(c.shape), self.epi_tile
)
epi_smem_layout = cute.slice_(self.c_smem_layout_staged, (None, None, 0))
tma_atom_c, tma_tensor_c = cpasync.make_tiled_tma_atom(
cpasync.CopyBulkTensorTileS2GOp(),
c,
epi_smem_layout,
c_cta_v_layout,
)
# Compute grid size
grid = self._compute_grid(c, self.cta_tile_shape_mnk, self.cluster_shape_mn)
|
3. cpasync.make_tiled_tma_atom 定义
(python/CuTeDSL/cutlass/cute/nvgpu/cpasync/helpers.py#L34)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
@dsl_user_op
def make_tiled_tma_atom(
op: Union[
CopyBulkTensorTileG2SOp,
CopyBulkTensorTileG2SMulticastOp,
CopyBulkTensorTileS2GOp,
CopyReduceBulkTensorTileS2GOp,
],
gmem_tensor: Tensor,
smem_layout: Union[Layout, core.ComposedLayout],
cta_tiler: Tiler,
num_multicast: int = 1,
*,
internal_type: Optional[Type[Numeric]] = None,
loc=None,
ip=None,
) -> Tuple[core.CopyAtom, Tensor]
|
4. cute.compile() :JIT 入口
(examples/python/CuTeDSL/blackwell/dense_gemm.py#L1740)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# ...
# Configure gemm kernel
gemm = DenseGemmKernel(
acc_dtype,
use_2cta_instrs,
mma_tiler_mn,
cluster_shape_mn,
use_tma_store,
)
torch_stream = torch.cuda.Stream()
stream = cuda.CUstream(torch_stream.cuda_stream)
# Compile gemm kernel
compiled_gemm = cute.compile(gemm, a_tensor, b_tensor, c_tensor, stream)
# Launch GPU kernel
# Warm up
for i in range(warmup_iterations):
compiled_gemm(a_tensor, b_tensor, c_tensor, stream)
# Execution
for i in range(iterations):
compiled_gemm(a_tensor, b_tensor, c_tensor, stream)
|
Lower路径:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# Python DSL
cute.copy(
tma_atom_a,
tAgA[(None, ab_producer_state.count)],
tAsA[(None, ab_producer_state.index)],
tma_bar_ptr=ab_pipeline.producer_get_barrier(ab_producer_state),
mcast_mask=a_full_mcast_mask,
)
# 转换为 MLIR Op
%result = cute_nvgpu.arch.copy.SM100.tma_load(
mode = #cute_nvgpu.tma_load_mode<tiled>,
num_cta = 1,
src_desc = %tma_descriptor_ptr,
dsmem_data_addr = %smem_ptr,
dsmem_bar_addr = %barrier_ptr,
coord = [%coord_0, %coord_1],
offsets = [],
multicast_mask = %mask
) : (...) -> ()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def compile(
self,
module,
pipeline: str,
cuda_toolkit: str = "",
arch: str = "",
enable_verifier=False,
):
"""Compiles the module by invoking the pipeline."""
try:
pm = self.passmanager.PassManager.parse(pipeline)
pm.enable_verifier(enable_verifier)
# Enable IR dump for dubug
pm.enable_ir_printing(print_after_change=True, enable_debug_info=True)
pm.run(module.operation)
|
- CuTe DSL Compiler – MLIR pipeline 配置
1
2
3
4
5
6
7
8
9
10
|
builtin.module(
cute-to-nvvm{
cubin-format=bin
opt-level=3
enable-device-assertions=false
toolkitPath=/usr/local/cuda
cubin-chip=sm_100a
},
external-kernel-for-gpu-launch
)
|
具体的Pass Pipeline:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
Python DSL
↓
1. CuteRemoveStaticArgs
2. CuteExpandOps
3. ConvertCuteAlgoToArch
4. CuteFoldStatic
5. InsertRangeInformation
6. Canonicalizer
7. CSE
8. LoopInvariantCodeMotion
9. ConvertCuteTypesInScfOps
10. ArithExpandOpsPass
11. SCFToControlFlow
12. ConvertToLLVMPass
13. SCFToControlFlow
14. Canonicalizer
15. CSE
16. ConvertVectorToLLVMPass
17. ConvertNVVMToLLVMPass
18. GpuNVVMAttachTarget
19. ExpandStridedMetadata
20. StripDebugInfo
21. ConvertGpuOpsToNVVMOps
22. GpuToLLVMConversionPass
23. Canonicalizer
24. ReconcileUnrealizedCasts
25. GpuModuleToBinaryPass
26. ExternalKernelForGpuLaunchPass
↓
LLVM IR
|
1. CuteRemoveStaticArgs

2. CuteExpandOps
将 cute.local_tilelower到cute.get_layout,tile维度计算、cute.make_shape(将原始flat layout转为嵌套的tiled layout)、Slice操作应用坐标偏移、View创建
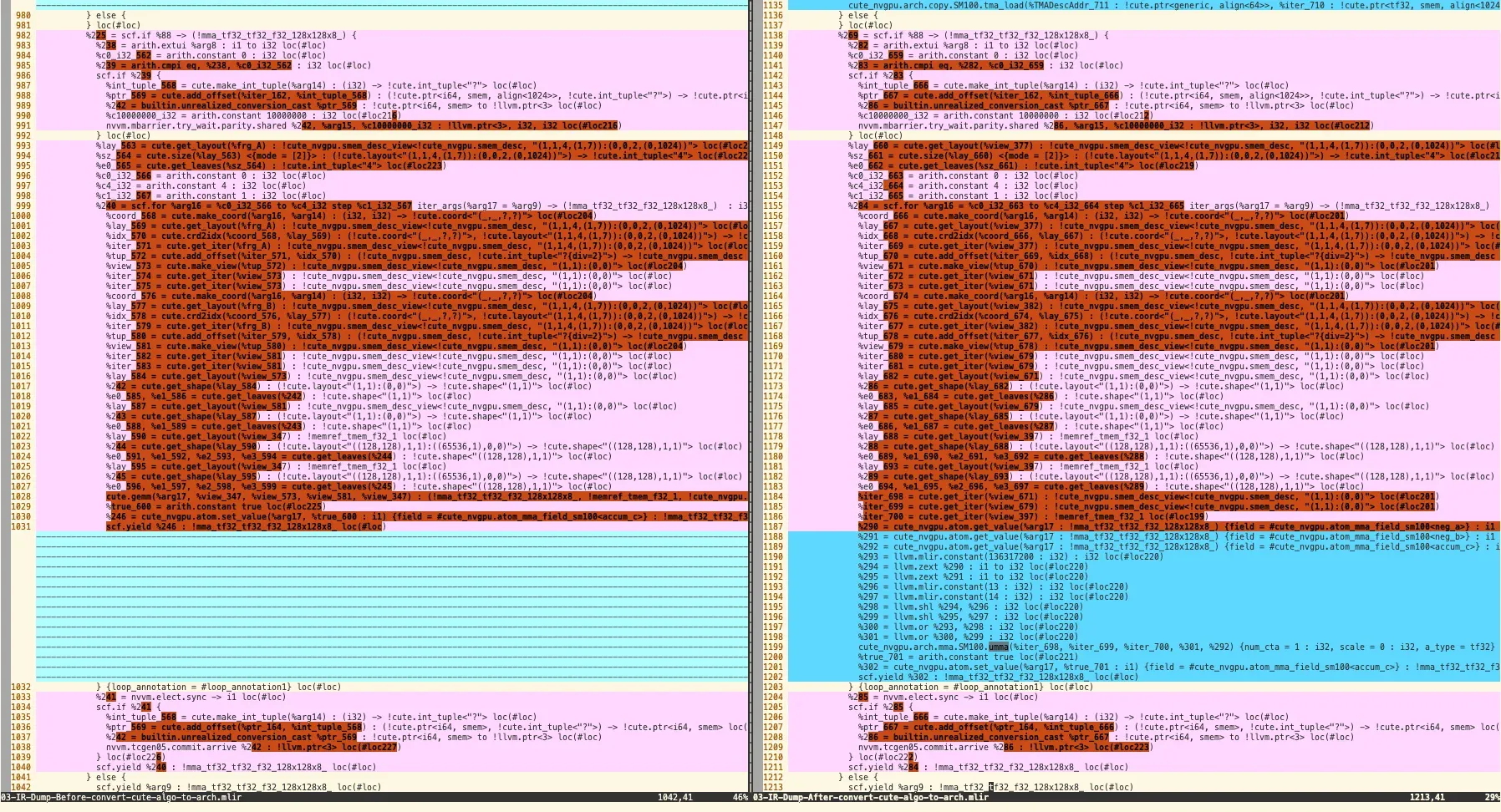
3. ConvertCuteAlgoToArch
很关键的pass,将 cutedsl 抽象 lower 到底层实现
- 3.1 Lower TMA Op
- Before: 用抽象好的
cute_nvgpu.atom.tiled_tma_load
- After:
- 生成完整的 TMA descriptor(128字节,16个 i64)
- 包含具体的地址计算、边界检查、swizzle 配置
- 设置 TMA 硬件参数(stride, shape, box extent等)
1
2
3
|
// 生成的 TMA descriptor 初始化代码
%llvm.getelementptr %89[0, 0] : (!llvm.ptr) -> !llvm.ptr
llvm.store %140, %141 : i64, !llvm.ptr // 存储各种 TMA 参数
|
- 3.2 生成 **UMMA (Unified Matrix Multiply Accumulate) **
- 生成 UMMA shared memory descriptor
- 配置 major mode (k-major)
- 设置 fragment layout
%ummaSmemDesc = cute_nvgpu.make_umma_smem_desc(…)
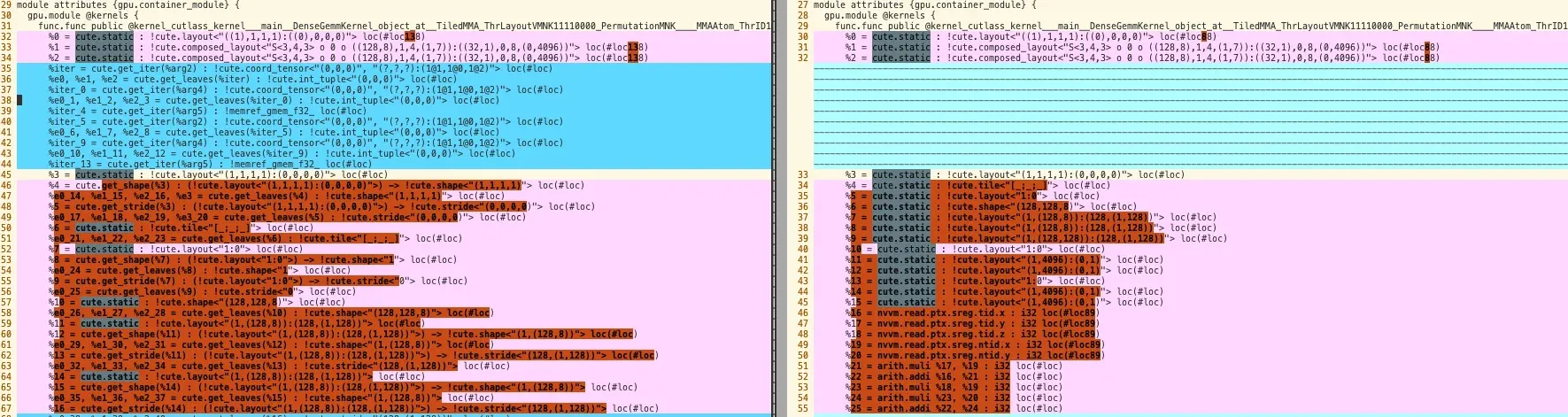
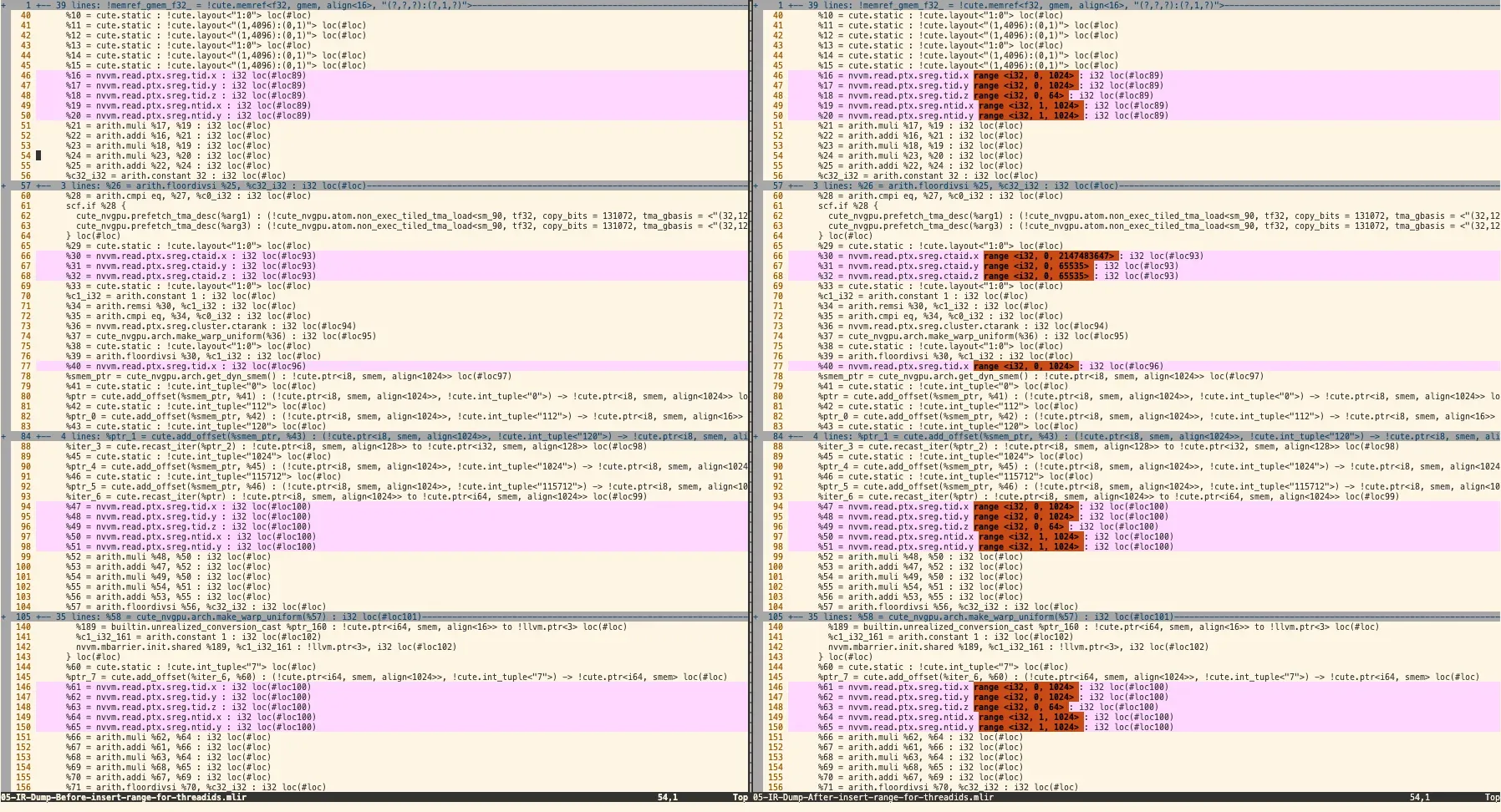
4. CuteFoldStatic
对 cute.static 修饰的常量进行折叠。
为读取 GPU 线程/块/网格 ID 的相关 nvvm.read.ptx.sreg.* 指令添加 range 属性。
(通用pass:6,7,8–略)
-
Canonicalizer
-
CSE
-
LoopInvariantCodeMotion
9. ConvertCuteTypesInScfOps
将在结构化控制流(scf)操作(如 scf.for 和 scf.if)中直接传递的 cute 自定义类型(mma_xxx),转换为底层的、更通用的类型(主要是 !llvm.struct)。
引入builtin.unrealized_conversion_cast:
在 scf 操作的边界插入了 builtin.unrealized_conversion_cast类型转换,用于告知编译器已知的类型不匹配问题(bypass)。
10. ArithExpandOpsPass
将高级、复合的arith dialect算术lower到基础 arith,比如ceildivsi向上取整 –> addi, subi, divsi, etc.
11. SCFToControlFlow
(略)SCF控制转换为CFG控制流。
12. ConvertToLLVMPass
将高层次抽象(cute、gpu、scf等)lower到 LLVM IR和NVVM IR
将 cute_nvgpu 中描述的抽象数据移动(cute.copy)、张量核计算(cute_nvgpu.mma_sm90)和同步操作,转换为具体的 nvvm 内置指令:
将 arith 方言中的通用算术运算(如 arith.addi)转换为等效的 llvm 方言运算(如 llvm.add):
将 cute.layout、cute.tiled_copy 等高层抽象类型,转换为 LLVM 能理解的指针(!llvm.ptr)、结构体(!llvm.struct)和向量(vector)等底层数据类型:
cf.br等 –> llvm.br (略)
(通用pass:略)
-
SCFToControlFlow
-
Canonicalizer
-
CSE
16. ConvertVectorToLLVMPass
(略)dense_gemm.py例子体现不出该pass的应有变换。
17. ConvertNVVMToLLVMPass
nvvm.prefetch.tensormap** -> **llvm.inline_asm将张量预取指令转换为 PTX 内联汇编:
nvvm.fence.mbarrier.init** -> **llvm.inline_asm将 mbarrier 初始化栅栏转换为 PTX 内联汇编:
nvvm.mbarrier.try_wait.parity.shared** -> **llvm.inline_asm将 mbarrier 的 try_wait 操作转换为一个包含循环等待的 PTX 内联汇编块:
18. GpuNVVMAttachTarget
附加 NVVM 目标信息:架构、编译选项等
(略)
20. StripDebugInfo
移除调试信息(loc)。
21. ConvertGpuOpsToNVVMOps
(略)dense_gemm.py例子体现不出该pass的应有变换。
22. GpuToLLVMConversionPass
gpu dialect –> llvm dialect,移除gpu方言
- Canonicalizer
(略)
24. ReconcileUnrealizedCasts
清理类型转换遗留问题,关联 pass-9:ConvertCuteTypesInScfOps。
25. GpuModuleToBinaryPass
生成 CUBIN,变换到 Pass 24 的IR,输入 JIT_executor 后将生成 .cubin,
26. ExternalKernelForGpuLaunchPass
(略)
Gen SASS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
--- a/python/CuTeDSL/cutlass/base_dsl/jit_executor.py
+++ b/python/CuTeDSL/cutlass/base_dsl/jit_executor.py
@@ -352,6 +352,12 @@ class JitExecutor:
cubin_data = cubin_data.split(b'bin = "')[1].split(b'">')[0]
cubin_data = self._get_escaped_cubin_bytes(cubin_data)
callback(sym, func_sym, cubin_data)
+
+ # dump cubin to file
+ import os
+ cubin_file_path = os.path.join("/workspace/cutlass/examples/python
/CuTeDSL/blackwell", f"{func_sym}.cubin")
+ with open(cubin_file_path, "wb") as f:
+ f.write(cubin_data)
return ir.WalkResult.ADVANCE
module.operation.walk(walk_gpu_binary_op)
|
Dump SASS
1
|
cuobjdump -sass kernel_xxx.cubin > kernel_xxx.sass
|
Gen PTX
官方暂时不支持。
需要 patch 一下 mlir/lib/Dialect/GPU/Transforms/ModuleToBinary.cpp 相关的 pass或改下 CuTe 传入的pipeline参数。
IR 变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// cute_nvgpu dialect
cute_nvgpu.arch.copy.SM100.tma_load(
mode = #cute_nvgpu.tma_load_mode<tiled>,
num_cta = 1,
src_desc = %desc_ptr,
dsmem_data_addr = %smem_addr,
dsmem_bar_addr = %bar_addr,
coord = [%x, %y],
multicast_mask = %mask
)
// Lower 到 NVVM Dialect
nvvm.cp.async.bulk.tensor.2d.shared.cluster.global.tile.mbarrier.arrive
%desc_ptr, [%smem_addr], %bar_addr, [%x, %y], %mask
|
1
2
3
4
5
6
7
|
// cute.Tensor 的 Layout 信息
!cute.layout<"((128,128),1,1):((65536,1),0,0)">
// 展开为地址计算
%offset = llvm.mul %i, 65536
%offset2 = llvm.add %offset, %j
%addr = llvm.getelementptr %base[%offset2]
|
1
2
3
4
5
6
|
// tcgen05.mma
cute.gemm(%tiled_mma, %acc, %a_frag, %b_frag, %acc)
// Lower 到 NVVM
nvvm.tcgen05.mma.ss.ss.t.f32.f16.f16.f32
%acc, %a_smem_desc, %b_smem_desc, %acc_tmem_desc
|
- NVVM dialect –> LLVM IR
- LLVM IR –> cubin
流程图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
Python 代码 (dense_gemm.py)
│
├─> cute.compile(gemm, ...)
│ │
│ └─> compiler.py::compile()
│ │
│ ├─> CompileOptions 解析
│ ├─> AST 预处理(可选)
│ └─> dsl.py::_func()
│ │
│ ├─> 参数类型转换
│ │ └─> cute.Tensor → memref<...>
│ │
│ ├─> generate_original_ir()
│ │ │
│ │ ├─> 创建 ir.Module
│ │ ├─> 构建 GPU Module
│ │ │ └─> @cute.kernel 装饰的函数
│ │ │ └─> gpu.func @kernel_...
│ │ │
│ │ ├─> 构建 Host Function
│ │ │ └─> func.func @dense_gemm
│ │ │ └─> gpu.launch_func
│ │ │
│ │ └─> 执行用户代码 funcBody(...)
│ │ └─> 生成 CUTE Dialect IR
│ │ ├─> cute.copy → TMA ops
│ │ ├─> cute.gemm → MMA ops
│ │ └─> cute.barrier → sync ops
│ │
│ ├─> 计算 module_hash (SHA256)
│ │
│ ├─> 检查缓存
│ │ ├─> Hit → 返回 JitExecutor
│ │ └─> Miss → compile_and_cache()
│ │
│ └─> compile_and_cache()
│ │
│ ├─> preprocess_pipeline()
│ │ └─> 添加 toolkitPath, sm-arch
│ │
│ └─> compile_and_jit()
│ │
│ └─> Compiler.compile()
│ │
│ ├─> PassManager.parse(pipeline)
│ │ │
│ │ └─> Pass Chain:
│ │ │
│ │ ├─> cute-to-linalg
│ │ │ └─> CUTE ops → Linalg ops
│ │ │
│ │ ├─> linalg-to-gpu
│ │ │ └─> Linalg → GPU Dialect
│ │ │
│ │ ├─> gpu-to-nvvm
│ │ │ └─> GPU → NVVM (含 tcgen05)
│ │ │
│ │ ├─> nvvm-to-llvm
│ │ │ └─> NVVM → LLVM IR
│ │ │
│ │ └─> llvm-to-cubin
│ │ └─> LLVM → CUBIN
│ │
│ └─> ExecutionEngine.create()
│ │
│ └─> 生成 CUBIN 二进制
│
└─> 返回 JitExecutor
│
└─> compiled_gemm(a, b, c, stream)
│
└─> ctypes 调用 C API
└─> CUDA Driver 加载并执行 kernel
|
CuTe C++
-
Host
make_tma_atom() Host TMA descriptors 创建 –> tma_atom_A/tma_atom_B
make_tma_descriptor()Copy_Atom()
-
Device
-
auto tma_partition(TMAAtom const& atom,
MulticastMode const& mcast_mode,
MulticastLayout const& mcast_layout,
STensor const& stensor,
GTensor const& gtensor);
-
initialize_barrier()
-
set_barrier_transaction_bytes()
-
copy(tma_atom.with(barrier), src, dst)
// Copy 派发到对应的copy模板函数
-
Copy_Atom::call(barrier, src, dst)
// CuTe C++ 底层封装 **SM90_TMA_LOAD::copy
-
SM90_TMA_LOAD_xD::copy(void const *desc_ptr, uint64_t* mbar_ptr, uint64_t cache_hint, void* smem_ptr, int32_t const& crd0)
- PTX asm inline
"cp.async.bulk.tensor.1d.shared::cluster.global.tile.mbarrier::complete_tx::bytes"
-
wait_barrier()
-
CUDA backend
-
CUBIN (SASS)
详解 Lower 路径
Host
make_tma_atom 模板展开: 创建 TMA 描述符
include/cute/atom/copy_traits_sm90_tma.hpp#L1365
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// Host 调用
Copy_Atom tma_atom_A = make_tma_atom(
SM90_TMA_LOAD{}, // Operation Tag
mA, // GMEM Tensor
sA_layout, // SMEM Layout
select<0,2>(mma_tiler) // Tiler
);
// 模板展开
template <class Operation, class GTensor, class SLayout, class TiledShape>
auto make_tma_atom(Operation const& op,
GTensor const& gtensor,
SLayout const& slayout,
TiledShape const& tiled_shape)
{
// 1. 编译期类型推导
using GEngine = typename GTensor::engine_type;
using SEngine = typename SLayout::engine_type;
using TValue = typename GTensor::value_type;
// 2. 编译期布局分析
auto tma_shape = transform_shape(tiled_shape, slayout);
auto tma_stride = transform_stride(gtensor.stride(), slayout);
// 3. 生成TMA描述符结构体(编译期计算偏移和配置)
auto tma_desc = make_tma_descriptor<Operation, TValue>(
gtensor.data(), // 基地址
tma_shape, // 传输shape
tma_stride, // 步幅
get_swizzle_bits(slayout) // Swizzle模式
);
// 4. 返回Copy_Atom类型(包含TMA描述符)
return Copy_Atom<Operation, TValue, decltype(tma_desc)>{tma_desc};
}
|
Device
tma_partition 根据 TMA 描述符对 tensor 进行分区
examples/cute/tutorial/blackwell/02_mma_tma_sm100.cu#L266
include/cute/atom/copy_traits_sm90_tma.hpp#L1387
tAgA:GMEM 源视图,mode-0: 单次TMA传输的完整块tAsA:SMEM 目标视图,mode-0: 扁平化的单次传输目标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
auto [tAgA, tAsA] = tma_partition(
tma_atom_A, // Copy_Atom<SM90_TMA_LOAD, ...>
Int<0>{}, // 非多播模式
Layout<_1>{}, // 非多播布局
group_modes<0,3>(tCsA), // SMEM目标
group_modes<0,3>(tCgA) // GMEM源
);
// 模板实例化
template <class TMAAtom, class MulticastMode, class MulticastLayout,
class STensor, class GTensor>
auto tma_partition(TMAAtom const& atom,
MulticastMode const& mcast_mode,
MulticastLayout const& mcast_layout,
STensor const& stensor,
GTensor const& gtensor)
{
// 编译期分支:是否多播
if constexpr (is_constant<0, MulticastMode>::value) {
// 非多播路径
return tma_partition_no_multicast(atom, stensor, gtensor);
} else {
// 多播路径(Tutorial 03)
return tma_partition_with_multicast(atom, mcast_mode, mcast_layout,
stensor, gtensor);
}
}
// 非多播实现
template <class TMAAtom, class STensor, class GTensor>
auto tma_partition_no_multicast(TMAAtom const& atom,
STensor const& stensor,
GTensor const& gtensor)
{
// 1. 提取TMA描述符配置
constexpr auto tma_shape = atom.shape(); // (_128, _64)
constexpr auto tma_stride = atom.stride(); // (_1, _128)
// 2. 重排GMEM张量为TMA期望的格式
// mode-0: 单次TMA传输的完整块 (flatten)
// mode-1+: 多次传输的迭代维度
auto tAgA_reordered = recast<tma_shape>(gtensor);
// ((TmaShape_M, TmaShape_K), RestModes...)
// 3. 重排SMEM张量为扁平化视图
auto tAsA_flat = flatten_to_tma_tile(stensor, tma_shape);
// (TmaSize_total, 1)
return cute::make_tuple(tAgA_reordered, tAsA_flat);
}
|
e.g.,
1
2
3
4
5
6
7
8
9
|
// 输入 tCgA: ((_128,_16),_1,_4,4)
group_modes<0,3>(tCgA) // → ((_128,_16,_4),4)
// ^^^^^^^^^^^^^ mode-0: MMA Tile MK
// ^ mode-1: Tiles_K
// TMA分区后 tAgA: (((_64,_128),_1),4)
// ^^^^^^^^^^^^ mode-0: 单次TMA传输块(flatten后8192元素)
// ^ mode-1: 内部虚拟维度(用于对齐)
// ^ mode-2: K tile迭代
|
copy() 的模板分发
入口调用:
1
2
3
4
5
|
if (elect_one_warp && elect_one_thr) {
copy(tma_atom_A.with(shared_storage.tma_barrier),
tAgA(_,k_tile),
tAsA);
}
|
Level 1: 通用 copy 入口
include/cute/algorithm/copy.hpp#L189
1
2
3
4
5
6
7
8
9
10
11
|
template <class... CopyArgs,
class SrcEngine, class SrcLayout,
class DstEngine, class DstLayout>
CUTE_HOST_DEVICE
void
copy(Copy_Atom<CopyArgs...> const& copy_atom,
Tensor<SrcEngine, SrcLayout> const& src, // (V,Rest...)
Tensor<DstEngine, DstLayout> & dst) // (V,Rest...){
copy_atom.call(src, dst);
}
|
Level 2: Copy_Atom::call
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// Check and call instruction, or recurse
template <class SEngine, class SLayout,
class DEngine, class DLayout>
CUTE_HOST_DEVICE
void
call(Tensor<SEngine,SLayout> const& src,
Tensor<DEngine,DLayout> & dst) const
{
static_assert(SLayout::rank == 1, "Expected rank-1 src tensor");
static_assert(DLayout::rank == 1, "Expected rank-1 dst tensor");
if constexpr (is_constant<NumValSrc, decltype(size(src))>::value ||
is_constant<NumValDst, decltype(size(dst))>::value) {
// Dispatch to unpack to execute instruction
return copy_unpack(static_cast<Traits const&>(*this), src, dst);
} else if constexpr (is_tuple<decltype(shape(src))>::value &&
is_tuple<decltype(shape(dst))>::value) {
// If the size of the src/dst doesn't match the instruction,
// recurse this rank-1 layout by peeling off the mode
// ((A,B,C,...)) -> (A,B,C,...)
return copy(*this, tensor<0>(src), tensor<0>(dst));
} else {
static_assert(dependent_false<SEngine>,
"CopyAtom: Src/Dst partitioning does not match the instruction requirement.");
}
}
|
Level 3: SM90_TMA_LOAD 特化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
template <class TValue, class TMADescriptor, class Barrier,
class SrcTensor, class DstTensor>
CUTE_DEVICE
void Copy_Atom<SM90_TMA_LOAD, TValue, TMADescriptor>::call(
Barrier const& barrier,
SrcTensor const& src, // tAgA(_,k_tile)
DstTensor & dst) // tAsA
{
// 编译期检查
static_assert(is_smem<DstTensor>::value, "Dst must be SMEM");
static_assert(is_gmem<SrcTensor>::value, "Src must be GMEM");
// 提取地址和大小(运行时)
uint64_t gmem_addr = reinterpret_cast<uint64_t>(src.data().get());
uint32_t smem_addr = cast_smem_ptr_to_uint(dst.data().get());
uint32_t tma_bytes = sizeof(TValue) * cosize_v<DstTensor>;
// 调用底层TMA copy函数
SM90_TMA_LOAD::copy(
tma_desc_, // TMA描述符(编译期常量内存)
barrier, // Barrier地址(运行时)
smem_addr, // SMEM目标地址(运行时)
gmem_addr, // GMEM源地址(运行时)
tma_bytes // 传输字节数(编译期常量)
);
}
|
PTX 内联汇编 生成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
struct SM90_TMA_LOAD_1D
{
CUTE_HOST_DEVICE static void
copy(void const* desc_ptr, uint64_t* mbar_ptr, uint64_t cache_hint,
void * smem_ptr,
int32_t const& crd0)
{
#if defined(CUTE_ARCH_TMA_SM90_ENABLED)
uint64_t gmem_int_desc = reinterpret_cast<uint64_t>(desc_ptr);
uint32_t smem_int_mbar = cast_smem_ptr_to_uint(mbar_ptr);
uint32_t smem_int_ptr = cast_smem_ptr_to_uint(smem_ptr);
cutlass::arch::synclog_emit_tma_load(__LINE__, gmem_int_desc, smem_int_mbar, smem_int_ptr);
#if defined(CUTE_ARCH_TMA_SM120_ENABLED)
asm volatile (
"cp.async.bulk.tensor.1d.shared::cta.global.mbarrier::complete_tx::bytes.L2::cache_hint"
" [%0], [%1, {%3}], [%2], %4;"
:
: "r"(smem_int_ptr), "l"(gmem_int_desc), "r"(smem_int_mbar),
"r"(crd0), "l"(cache_hint)
: "memory");
#else
asm volatile (
"cp.async.bulk.tensor.1d.shared::cluster.global.mbarrier::complete_tx::bytes.L2::cache_hint"
" [%0], [%1, {%3}], [%2], %4;"
:
: "r"(smem_int_ptr), "l"(gmem_int_desc), "r"(smem_int_mbar),
"r"(crd0), "l"(cache_hint)
: "memory");
#endif
#else
CUTE_INVALID_CONTROL_PATH("Trying to use tma without CUTE_ARCH_TMA_SM90_ENABLED.");
#endif
}
// ...
}
|
Appendix
1
2
3
4
5
6
7
8
|
➜ cutlass git:(main) ✗ nm -D /root/wkspace/cutlass/_mlir/_mlir_libs/_mlirExecutionEngine.cpython-313-x86_64-linux-gnu.so | grep -i "execution\|nvptx\|ptx" | head -20
0000000000008038 T PyInit__mlirExecutionEngine
U mlirExecutionEngineCreate
U mlirExecutionEngineDestroy
U mlirExecutionEngineDumpToObjectFile
U mlirExecutionEngineLookupPacked
U mlirExecutionEngineRegisterSymbol
|
CuTe DSL passManager pipeline dump:
1
2
3
4
5
6
7
8
9
10
11
|
[Debug] Using compilation pipeline: builtin.module(
cute-to-nvvm{
cubin-format=bin
opt-level=3
enable-device-assertions=false
link-libraries=
toolkitPath=/usr/local/cuda
cubin-chip=sm_100a
},
external-kernel-for-gpu-launch
)
|
 Albresky's Blog
Albresky's Blog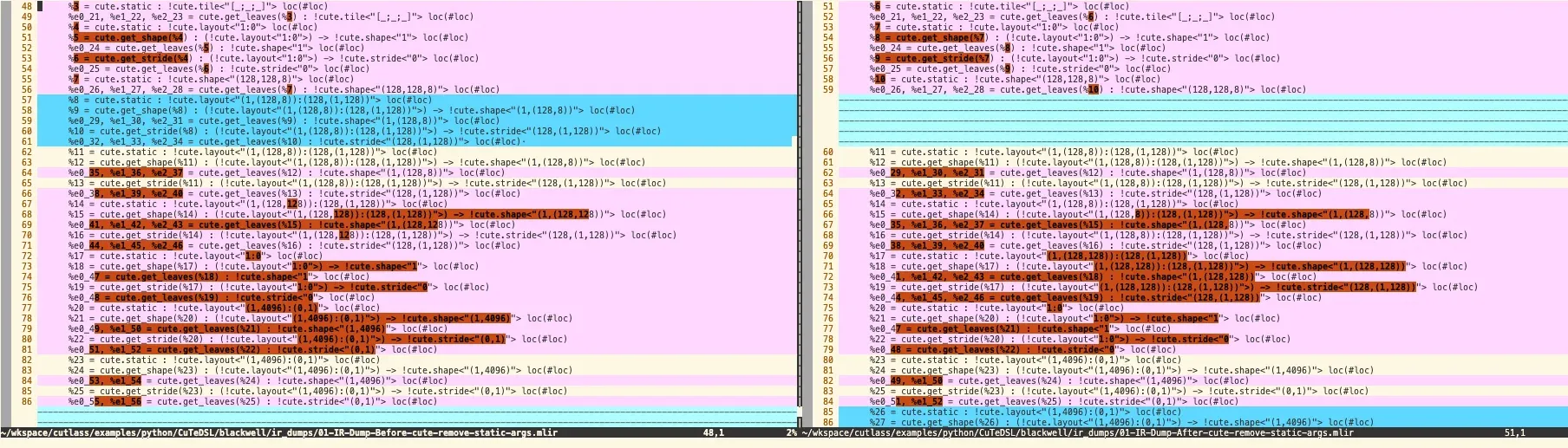

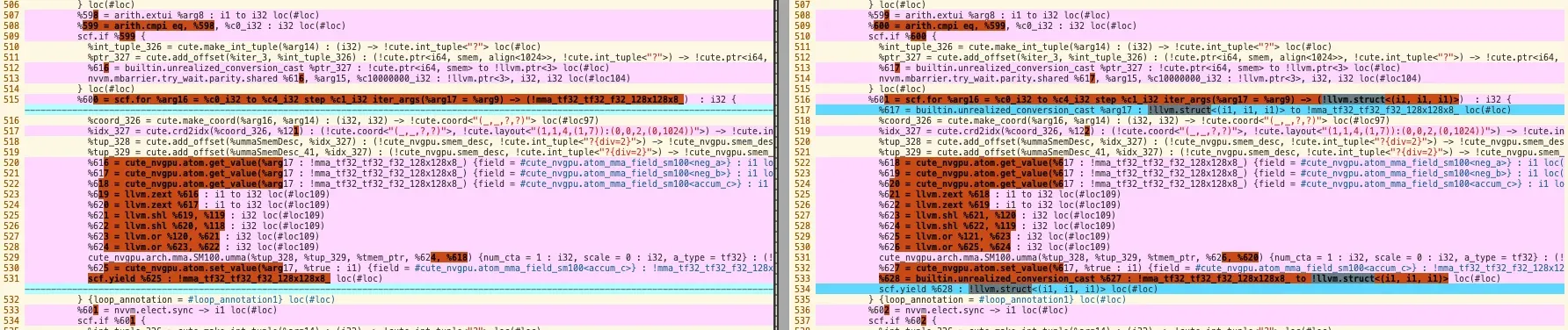
 在
在 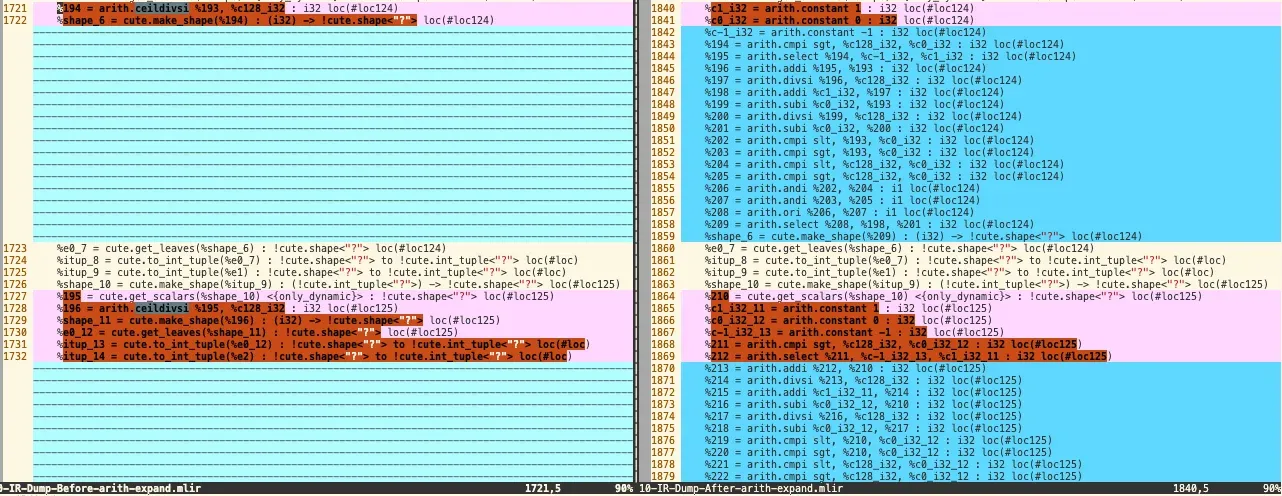
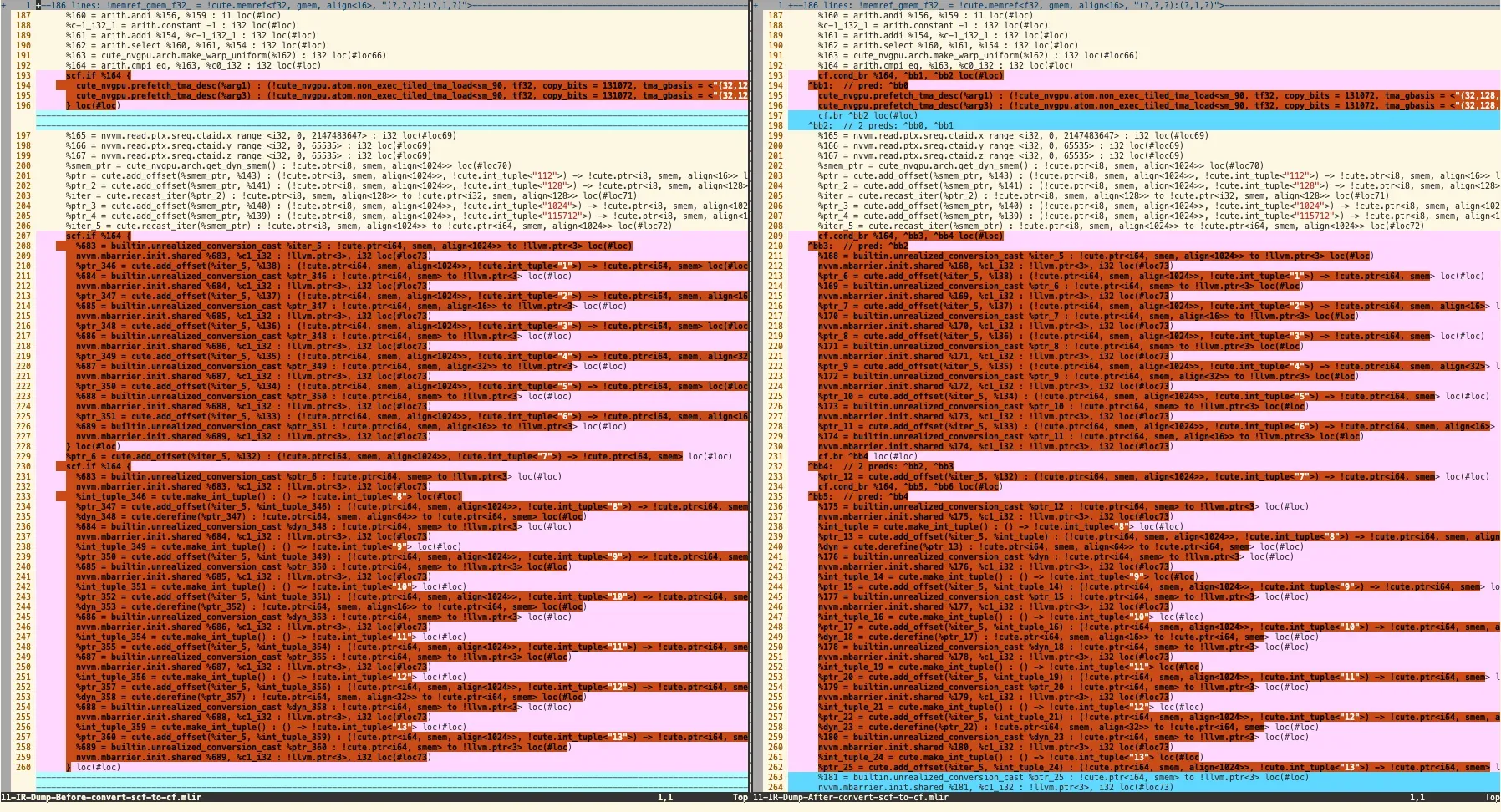
 将
将 
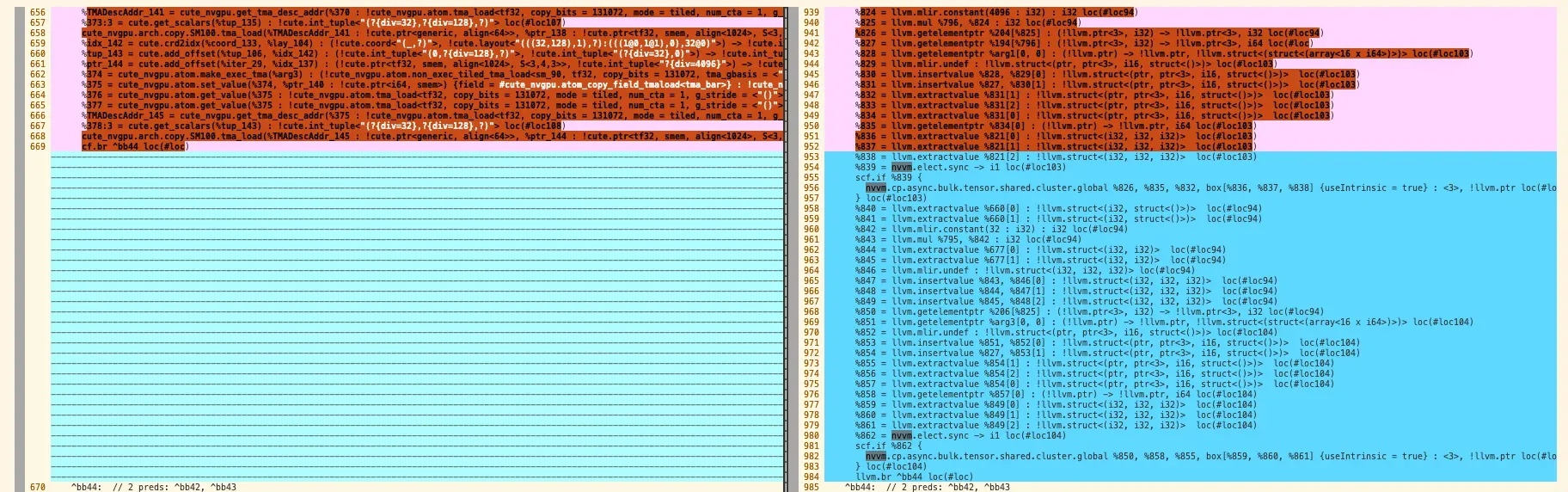 将
将 








 支付宝
支付宝
 微信
微信
