 Albresky's Blog
Albresky's BlogMLIR-AIE A-Z | 教程篇
从 A 到 Z, 快速上手 MLIR-AIE。
MLIR-AIE 作为面向 AIE 的 dialect,可用于生成低层次的 AIE 代码,包括 AIE Core、AXI-Switches、ShimDMA 等。本系列教程的步调几乎与官方 tutorials 保持一致。
前期基础准备可参考(假设已有 ADF/AIE_API 的编程经验):
1. Modules, tile, buffer, core and lock
在 AIE 的 MLIR 中,AIE 阵列下的所有组件、参数等均被包含在一个 Module 块下面,其代码存储在以 .mlir 为后缀的文件中。此外 LLVM 项目的 .lit 文件被用于测试。
下面是一个 Module 示例的声明(后面的阐述将以此为主要参考):
|
|
Tile 的内部组件
Tile 的定位使用 (col, row) 的形式进行声明。需要注意的是, MLIR 中对 tile 定位时,row=0 的 tiles 表示 shim tiles,而 ADF 编程中的它们依然是普通 tiles。因此,在MLIR 中的 AIE tiles 在 row 维度,是从 index=1 开始的。
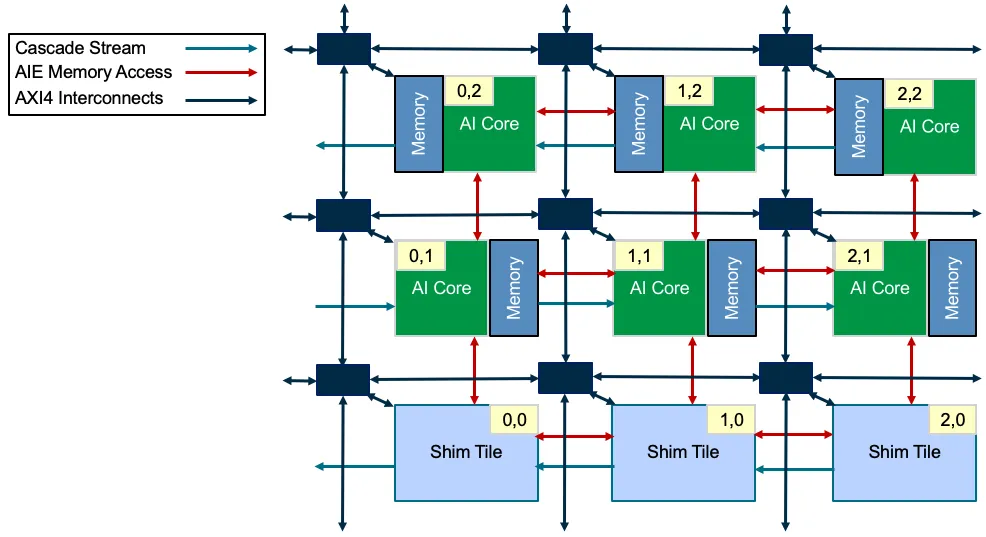
AIE 中的物理 tile 用 %tileName = aie.tile(col, row) 进行声明,而每个 tile 的内部组件主要有 core, buffer 和 lock 三个。其中,core 和 buffer 的声明方式如下:
|
|
core:
AIE 的 kernel function 是定义在 core的 body中的,这个body 是由 AIE dialect 特定的操作组成的,同时也包括了其他 MLIR 支持的 dialects,如 arith 和 memref。这些 dialects 也可以包括其他的,比如 arctan。需要注意的是,MLIR 不是一种编程语言,而是一种中间表示,因此简单操作的语法可能看起来有些繁琐,但是它的设计是为了捕捉一套强大的操作。此外,mlir-aie 还支持与外部编译的 kernel 代码链接,这个过程可以在 tutorial 9 中详细探讨。这个过程允许将自定义的 kernel 直接包含在 mlir-aie 定义的设计中。
buffer:
buffer 的 body 则用于声明 buffer 名称,memref内部用于指定数据的深度和数据类型。多个声明在同一个 tile 中的 buffer 默认会按声明顺序依次 mapping 到 该 tile 的本地存储中。注意,AIE 的程序栈(Program Memory,PM)是固定大小 1KB 的,分配的 Buffer 是从 PM 之后的更高地址开始分配。(其实在 Vitis AIE 中,这个PM stack大小和位置是可以指定的,MLIR-AIE 似乎暂时还没有实现相关的 dialect)。
lock:
lock 组件作用于不同 tile 间、tile 与 ps(host) 间 的数据同步。lock 是每个 AIE Tile 内部的一个物理组件,每个 AIE Tile 内部有 16 个 locks,且每个 lock 有两个状态(0 and 1,它们对应的含义并没有显示指定)。lock 的设定是为了保证不同 access 对同一 local memory 进行访问的同步控制,每个lock 可以被其所属 tile 的相邻的 3 个 tile 访问(与 local memory 访问规则一致)。
其声明方式为:
|
|
在获取/释放这个锁时,只需记住:在 acquire 一个锁前,只有这个锁的状态和 acquire 指定的状态一致时,锁才会获得;在 release 一个锁时,可以任意决定 release 后的锁的value。
比如:当前 lock 的值为 1,那么 acquire=1时这个锁才会被获取;当 release 一个锁时,可以任意将 lock 的值置为 0 或 1。
锁可以在 core 或者 buffer 的 body 中使用,用于同步数据的读写。在 buffer 的 body 中,lock 用于保证 buffer 的读写操作的原子性。在 core 的 body 中,lock 用于保证 core 内部操作的执行顺序。比如:
|
|
执行官方例程下面的 tutorial-1/Makefile,可以通过 aiecc工具(封装了 aie-opt、aie-translate)将 MLIR 代码编译成 AIE core 上的可执行文件 core_1_4.elf。流程上, aiecc 会先将 mlir-aie 的 IR 转成 LLVM IR,然后再通过 Vitis 的 xchesscc 编译工具生成 AIE Core 上的 ELF 可执行文件。
更多关于 aiecc 工具的编译选项,可参考博客 MLIR-AIR 工具构建与配置。
后续示例中会有更多关于 core、buffer 和 lock 更复杂的使用场景。
2. Host 配置、仿真与 Profiling
a)Host.cpp 配置
当使用 -aiesim 选项启用 aie 仿真时,会生成 ./sim 目录以及 aie.mlir.prj/aie_inc.cpp 文件。该文件中包含了一系列 host 端用于控制 AIE 的配置 API:
| Host Config API | 描述 |
|---|---|
aie_libxaie_ctx_t |
描述 AIE 配置信息和数据类型的结构体 |
mlir_aie_init_libxaie() |
创建并初始化 aie_libxaie_ctx_t struct |
mlir_aie_init_device(_xaie) |
初始化 AIE 阵列 |
mlir_aie_configure_cores(_xaie) |
重置所有相关的 AIE 内核、载入 ELF,并重置 locks 为零 |
mlir_aie_configure_switchboxes(_xaie) |
配置 AXI_Switches |
mlir_aie_configure_dmas(_xaie) |
配置 DMA |
mlir_aie_initialize_locks (_xaie) |
初始化 locks 的值 |
mlir_aie_clear_tile_memory(_xaie, int col, int row) |
清除指定 Tile 的 Local Memory |
通过上述 Host API可以将 AIE 阵列、内核、Switches、DMAs、锁都初始化好:
|
|
唯剩负责 Runtime 数据传输任务的 ShimDMAs 未初始化。在 VCK190 平台中,需要在 Host 上利用 LibXAIEngine 驱动对其进行初始化,完成三个任务:
- 分配 buffer(虚拟 DDR 地址,共享虚拟内存)
- 配置 shim ShimDMAs
- 同步物理 DDR 地址到虚拟 DDR
示例:
|
|
| Host Config API | Description |
|---|---|
mlir_aie_mem_alloc(_xaie, ext_mem_model_t buf, int size) |
根据 buf 句柄、字数(字长为 4 字节) 动态分配内存 |
mlir_aie_external_set_addr_<symbol name>(u64 addr) |
设置 Shim DMAs 中 外部 buffer 的虚拟内存地址 addr |
mlir_aie_configure_shimdma_<location>(_xaie) |
根据提供的虚拟内存地址 addr 完成对 Shim DMAs 的外部 buffer 配置 |
mlir_aie_sync_mem_dev(ext_mem_model_t buf) |
将虚拟内存地址的数据同步至 Shim DMAs 访问的外部 buffers。在仿真中,通常在主机侧更新完虚拟内存的数据后,需先执行此操作,以确保 Shim DMAs 的外部 buffers 能够读写主机侧最新修改的数据。 |
mlir_aie_sync_mem_cpu(ext_mem_model_t buf) |
将Shim DMAs 访问的外部 buffers 的数据同步至虚拟内存地址空间。在仿真中,通常在主机侧需要从 AIE 读取最新的外部 buffer 数据前,执行此操作。 |
设备初始化、数据准备完毕后,可以开始执行 AIE 阵列的仿真:
|
|
| Host Config API | Description |
|---|---|
| mlir_aie_start_cores (_xaie) | 重置并启用设计中的所有 AIEs |
| mlir_aie_print_tile_status (_xaie, int col, int row) | 将 Tile(col, row) 的状态打印到标准输出 |
| mlir_aie_print_shimdma_status (_xaie, int col, int row) | 将 Shim DMA(col, row) 的状态打印到标准输出 |
| mlir_aie_acquire_<symbolic_lock_name > (_xaie, int value, int timeout) | 根据给定的锁的符号名称 symbolic_lock_name 和 值 value 申请锁,申请的超时时间为 timeout (ms)。当超时为 0时,将进行非阻塞式申请锁(立马返回申请结果);当超时大于 0 时,将持续申请锁,直至成功或超时 |
| mlir_aie_release_< symbolic lock name > (_xaie, int value, int timeout) | 根据给定的超时值 timeout 释放锁,超时值为 0 时,立马返回申请结果;大于 0 时,超时结束后释放锁 |
| mlir_aie_read_buffer_< symbolic buffer name > (_xaie, int index) | 根据 buffer 的符号名和索引从 DM 读取数据 |
| mlir_aie_write_buffer_< symbolic buffer name > (_xaie, int index, int value) | 根据 buffer 的符号名和索引向 DM 写入数据 |
| mlir_aie_check (s, r, v, errors) | 宏定义,用于检查值 v 与预期参考值 r 之间的关系。如果断言失败,则输出错误消息包括字符串 s,并递增 errors |
b)aiesimulator
在 MLIR-AIE 中,顶层 Module 下面会通过 aie.device() 绑定指定 device:
|
|
支持的 devices 有:
- TK_AIE1_VC1902
- TK_AIE1_Last
- TK_AIE2_VE2302
- TK_AIE2_VE2802
- TK_AIE2_NPU1
- TK_AIE2_NPU1_1Col
- TK_AIE2_NPU1_2Col
- TK_AIE2_NPU1_3Col
- TK_AIE2_NPU1_4Col
- TK_AIE2_NPU1_Last (TK_AIE2_NPU2)
- TK_AIE2_NPU2_Last (TK_AIE2_Last)
使用如下命令生成 Vitis aiesimulator 的仿真工作目录 ./sim:
|
|
./sim 目录中包含一个 test.cpp 经过 一系列 wrap 后的二进制文件 ./sim/ps/ps.so。
此时即可使用 aiesimulator 工具进行仿真:
|
|
3. 通过 DM 通信
熟悉 Vitis ADF 编程的话这一块就没什么好讲的。相邻 Tile 间访问共享 DM 的规则,主要就一点:与彼方本地 DM 直接相邻的 AIE Core,可以共享彼方的 DM。
以偶数行为例,相邻的两个 Tile 的核心、DM 排列(West-to-East)为:(A-DM|A-Core, B-DM|B-Core),那么 Tile-A 就可以直接共享 Tile-B 的 DM,因为 Tile-A 的 Core 与 Tile-B 的 DM 直接相邻;反之,如果是奇数行,其排列为 (A-Core|A-DM, B-Core|B-DM),那么 Tile-B 就可以共享 Tile-A 的 DM。
DM 的共享规则很简单,这一节主要介绍利用 MLIR-AIE 进行共享 DM 方式进行通信时的 lock 使用,进一步深化对锁的认识。
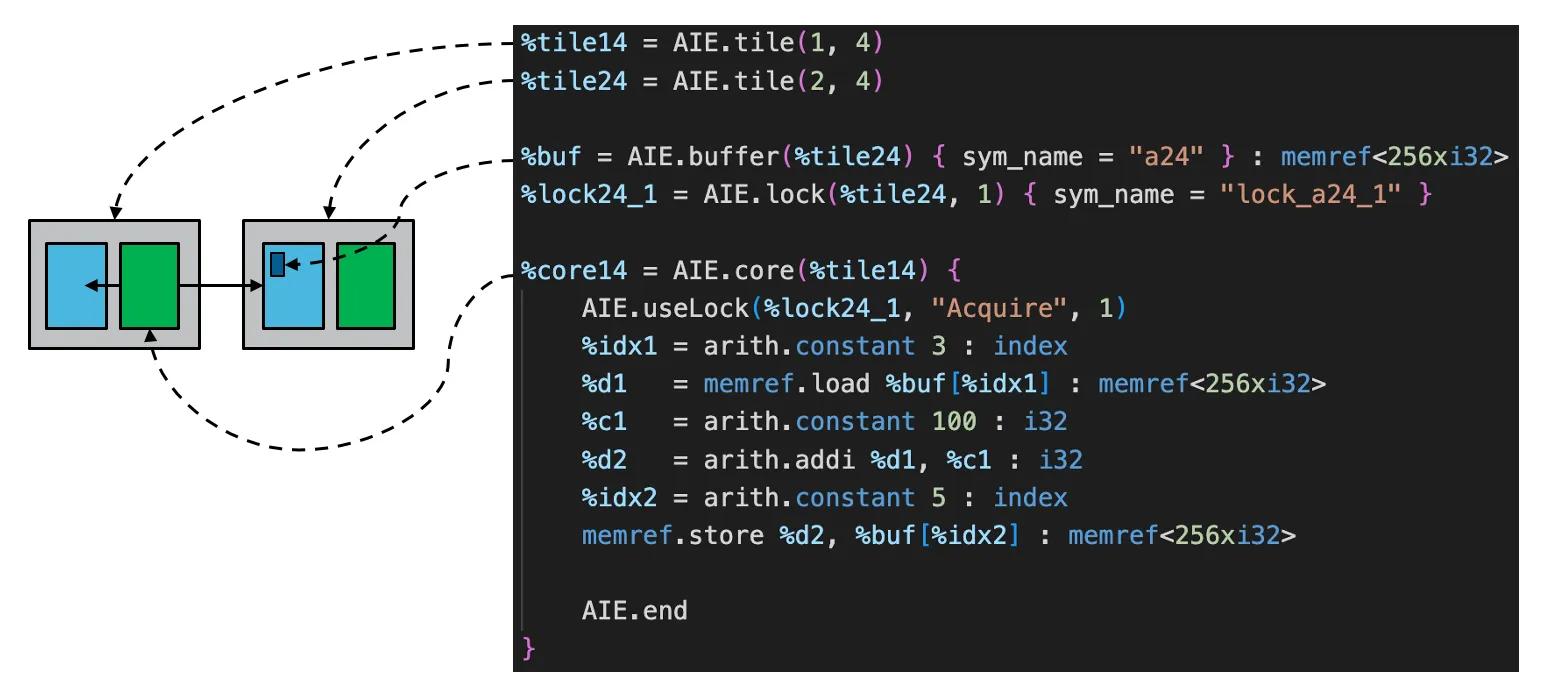
下面是一段用几个 locks 控制两个 Tile 间的数据同步的示例,
其流程可概括为:
- 创建 Tiles
- 声明 buffers
- 声明 locks
- 定义 Tiles 的 core function
- 在 function 中使用 locks 控制数据同步
其完整的 MLIR 代码如下:
|
|
Object-FIFO(DM) 通信
使用原生的锁来控制数据流的同步,直观但不够简洁。MLIR-AIE 提供了一种更高层次的抽象:objectFIFO,用于简化相邻 Tile 间的数据流的同步。该抽象在声明过后,MLIR-AIE后续还是会通过一系列 passes 将其 lowering 到最基础的三个组件(包括 buffer 和 locks 的声明和初始化、locks 值更新等)。
objectFIFO 的声明方式如下:
|
|
它需要显式声明 fifo 的生产者(唯一)和消费者(至少一个),以及 FIFO 的深度和元素数据类型。
在 objectFIFO 简化上述原生声明示例时,其流程便可简化为:
- 创建 Tiles
- 声明 objectFIFOs
- 定义 Tiles 的 core function
- 在 function 中使用 objectFIFO 控制数据同步
在申请和释放锁时,需要指定是生产者还是消费者,同时说明访问的 FIFO 元素的位置。
|
|
下面是使用 objectFIFO 后的示例代码:
|
|
object-FIFO 中的 lowering
在 MLIR-AIE 中,每个 objectFIFO 会被 lowering 到基础组件的一组 buffer 和 lock ,而 aie.objectfifo.acquire 和 aie.objectfifo.release 会被 lowering 到 aie.use_lock 操作中的 Acquire 和 Release,而 ObjectFIFO 中的 acquire 的 Produce 和 Consume 对应到 use_lock 进行 Acquire 时的 锁 value。比如:
当我们声明一个 objectFIFO 时,其 lowering 到 uselock 的过程如下:
- 声明 objectFIFO。生产者:tile14,消费者:tile24,深度:1,FIFO大小:256 × int32
|
|
经过 pass:aie-opt --aie-objectFifo-stateful-transform 后,其 lowering 后的形式为:
注意,在使用 lowering pass 前,还需要应用规范化 pass 以确保当前 Module 的目标设备受支持: 先
aie-opt --aie-canonicalize-device <path to mlir source file>, 然后aie-opt --aie-objectFifo-stateful-transform <path to mlir source file>
|
|
- 在 Core Function 内声明生产者请求获得锁的子视图
|
|
其 lowering 后的形式为:
|
|
- 在 Core Function 内声明释放生产者的锁
|
|
其 lowering 后的形式为:
|
|
结合下图,对 ObjectFIFO 的申请、释放元素 1 的操作,总结如下:
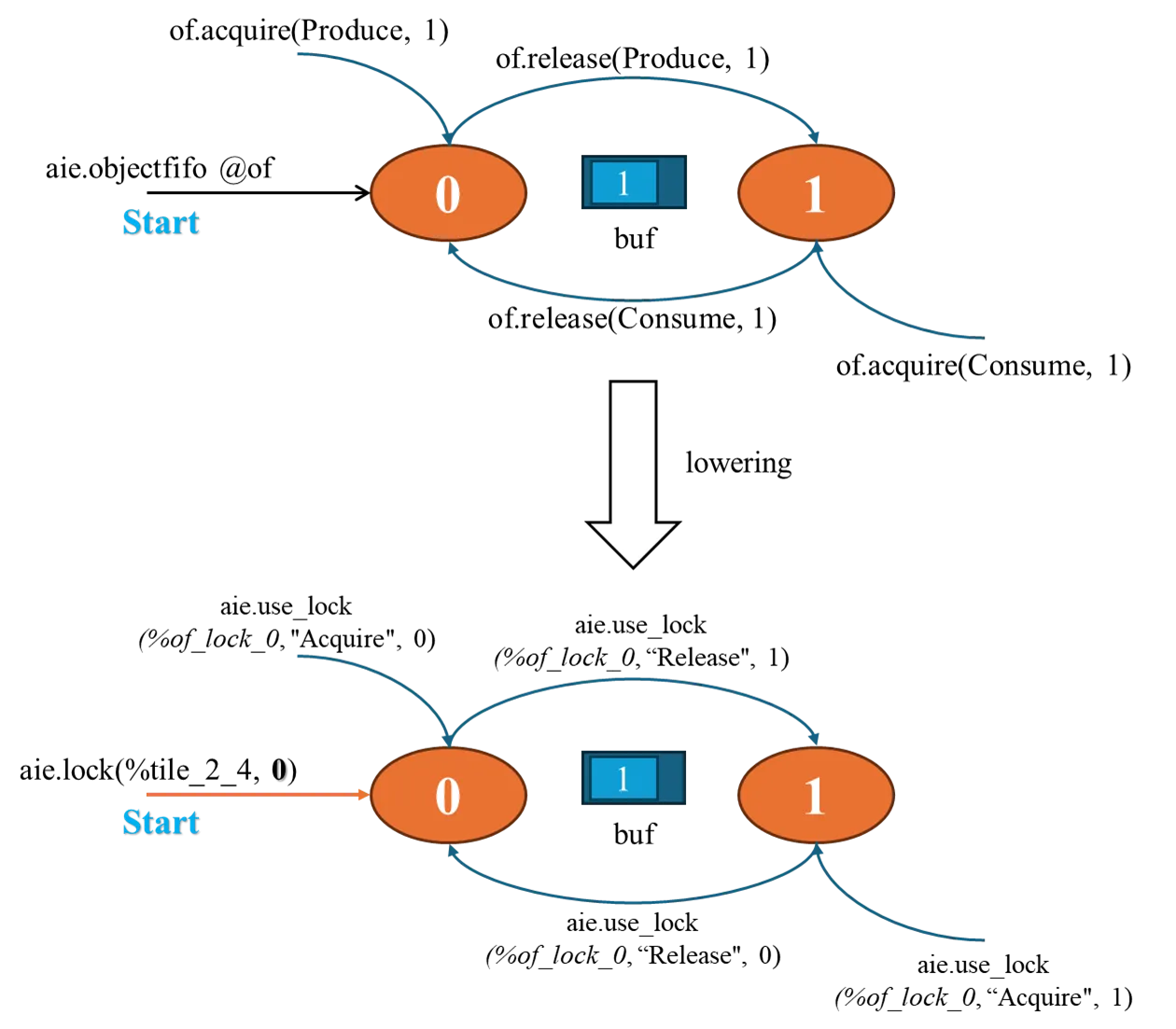
|
|
4. 通过 AXI4-Switch & Tile DMAs 通信
本节介绍通过 Flow 来指定 AXI4-Switch 数据流的通信规则、利用 Tile DMAs 控制 Tile 本地的 Mem 读写规则,以及使用 aie.switchbox 来细粒度地配置 AXI4-Switch。对应的硬件结构参考 AM009。
数据流 Streams
数据流 Streams 是 AIE 的一个重要特性。它们是 运行在 AIE 内核时钟频率(如 1.25 GHz)32-bit 流。含 4 个 channels 从水平和垂直方向进出 AXI4-Switch(除了从 South 的垂直输入和 North 的垂直输出,共有 6 个 channels)。AIE Core 有 2 个输入和 2 个输出 Stream 端口连接到其本地的 AXI4-Switch,但将大块数据推入和推出 Stream 网络的更常见方式是使用 tile DMA。AIE Core 负责访问本地内存 DM,而 tile DMA 则将数据从 DM 搬运到 AXI4-Switch。
逻辑路由 (flow)
AIE 的 AXI4-Switch 用于在 AIE Tiles 之间(相邻或不相邻)进行数据路由。每个 AXI4-Switch 有 18 个输入 channels 和 18 个输出 channels,该 AXI4-Switch 可以通过 channels 连接到其邻近的 SwitchBox、tile DMA、AIE core 和其内部的 FIFO。
AXI4-Switch 有两种工作模式,本节我们聚焦于 电路交换 模式,包交换模式将在后续第 6 节中介绍。
- 电路交换
- 包交换
电路交换模式用于在 AXI4-Switch 中预设一个固定的路由表,指定数据从 AXI4-Switch 的 1 个输入 channel 被路由到 1 个或多个输出 channels。电路交换模式的路由表由 DMAs 进行数据传输,该表在用户设计时就被配置好,运行时不会改变。
路由表是一个由 源端口(来自 Switch-src) 到 目的端口(来自 Switch-dest) 的路由语句构成的集合,每个路由语句被抽象为一个 flow,通过 aie.flow 操作进行声明。
其声明原型如下:
|
|
例如,声明一组 tile(7, 1) 和 tile(7, 3) 之间的路由:
|
|
需要注意的是,尽管我们在 IR 中只声明了两个 tile 的 AXI4-Switch(71 和 73),但该 flow 被 lowering 到实际 AIE 阵列时,路径中可能包含 tile(7, 2) 的本地 AXI4-Switch。这是因为在构建从 src 到 dest 的路由路径时,MLIR-AIE 的 pass 会利用路由算法来寻找最优的路径(PathFinder Pass)。
AIE 中配置 AXI4-Switch 的 flow 时,可用的 Buddle 名称与对应的 Channels 数量如下:
| Bundle | Channels (In) | Channels (Out) |
|---|---|---|
| DMA | 2 | 2 |
| Core | 2 | 2 |
| West | 4 | 4 |
| East | 4 | 4 |
| North | 4 | 6 |
| South | 6 | 4 |
| FIFO | 2 | 2 |
| Trace | 1 | 0 |
Tile DMAs
每个 AIE Tile 的本地 AXI4-Switch 中,有 2 个 DMAs 负责 AXI4-Switch 的数据搬运,且每个 DMA 内部有 1 个 write channel 和 1 个 read channel,因此 1 个 AXI4-Switch 共提供了 4 个 datamovers(DMAs 的 channels 各由 1 个 datamover 负责数据传输)。此外,每个 AXI4-Switch (就是这 4 个 datamovers)还提供了 16 个 缓存描述符(Buffer Discriptor,BD),用于描述每个 AIE Tile 本地 DM 中的 8 个物理 banks 的 write 和 read。
下面是一段利用 dma_start 和 dma_bd 声明 DM 行为的示例:
|
|
DMA 声明
在 aie.mem 中使用 BD 前,得先通过 aie.dma_start 声明一个 DMA,其原型如下:
|
|
dma_start 的参数如下:
| 参数 | 用途 |
|---|---|
$channelDir |
DMA 的方向 (存储器 -> 流 MM2S, 流 -> 存储器 S2MM) |
$channelIndex |
DMA channel (0, 1). 第一代 DMA 本地有两个 channel(R&W) |
$dest |
声明链的第一个 BD |
$chain |
声明链的下一个 BD。一般指向 aie.end,但是如果有多个 dma_start,也可以指向后一个 dma_start 的 label |
Buffer descriptors(BD)
如前所述,每个 Tile 中可对其 DM 声明 16 个 BD,aie.dma_bd 的声明原型如下:
|
|
| 参数 | 用途 |
|---|---|
$buffer : type($buffer) |
DMA 进行读/写的 Buffer,形如 memref (类似 %buf14: memref<256xi32>) |
%offset |
DMA 读/写 Buffer 时的内存偏移量 |
%len |
DMA 读/写时的 字节(Byte) 数量 |
%AB |
默认值为 0,表示不启用 。该参数说明 BD 用于描述 A 还是 B 的 buffer |
从上面的代码中可以看到 dma_bd 被 lock 包裹起来了,以控制其同步性。但这里不是必须的。
下面是一段完整的 Tile DMA 的示例,通过 2 个 DMA 和 4 个 BD 来实现 Ping-Pong Buffer:
|
|
switchbox
前文所述的 Flow 抽象用于在更高层次的逻辑层面指定两个端点间的路由规则,而对于硬件层面的 AXi4-Swtich,我们需要使用 switchbox 来进行细粒度的控制。
AIE 阵列中每个 AIE Tile 本地均有一个 AXI4-Switch,并且所有的 AXI4-Switch 之间(R&W)通过 32-bit 的 Stream 互相连接。3,如下声明示例从路由路径的每一个 AXI4-Switch 节点描述了 channel 的连接方式,实现了从 tile(1, 4) 的 DMA 0-channel 到 tile(3, 4) 的 DMA 1-channel。
|
|
5. 通过 Shim DMAs & DDR 通信
前面的通信方式均局限于 AIE 阵列内部的 DM 进行数据传输(类似 CPU 的多级内存结构的 L1 Cache),实际场景中还存在 DM 空间不够大,需要从 Global Memory 进行数据读写的情况(L3 Cache),这就需要用到 AIE 阵列中的 Shim DMAs(即 MLIR-AIE Dialect 中 row=0 的 AIE Interface Tiles)。
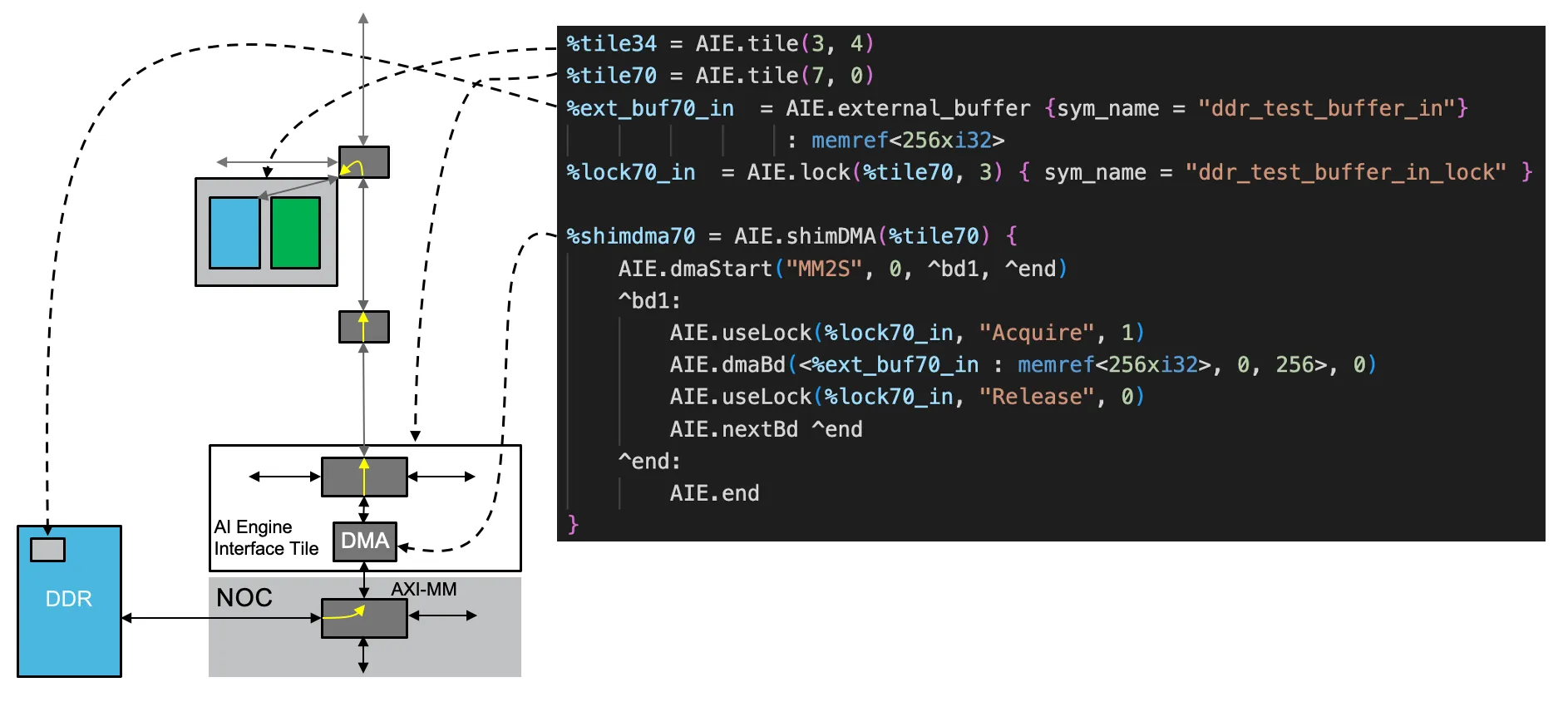
为了实现从 DDR 到 AIE Tile 的通信,需要从三个方面进行干预:
- Shim DMA 与 外部 Buffers
- NoC 片上网络
- 主机端对 DDR 的虚拟地址转换
Shim DMA
为了从 AIE 阵列与 DDR 进行通信,需要 Shim DMAs 做媒人,而 Shim DMAs 是与 NoC Interfaces (或 PL Interfaces)直接相连的。Shim DMAs 在 MLIR-AIE 中的抽象和行为描述与 Tile DMAs 类似,不同的是 BD 描述符这里是在 shim_dma 中定义,而非在 mem 中。
|
|
Shim DMAs 内部的 DMA、BD、channels 数量等,与 Tile DMAs 一致。只有其本地的 AXI4-Switch 与 Tile DMAs 有区别,Shim DMAs 的 switchbox 描述符如下:
| Bundle | Channels (In) | Channels (Out) |
|---|---|---|
| DMA | 2 | 2 |
| West | 4 | 4 |
| East | 4 | 4 |
| North | 4 | 6 |
| South | 8 | 6 |
| FIFO | 2 | 2 |
| Trace | 1 | 0 |
另外,在 VCK190 中,仅这些列号的Tile 具备 Shim DMAs:(2,3,6,7,10,11,18,19,26,27,34,35,42,43,46,47)。
外部 Buffers
在 shim_dma 内部的 BD 定义时,还需提前进行外部 buffer (比如 DDR)的声明:
|
|
外部 buffer 的声明与 Tile 内部的 buffer 声明类似,不同点在于它无需指定 tile。
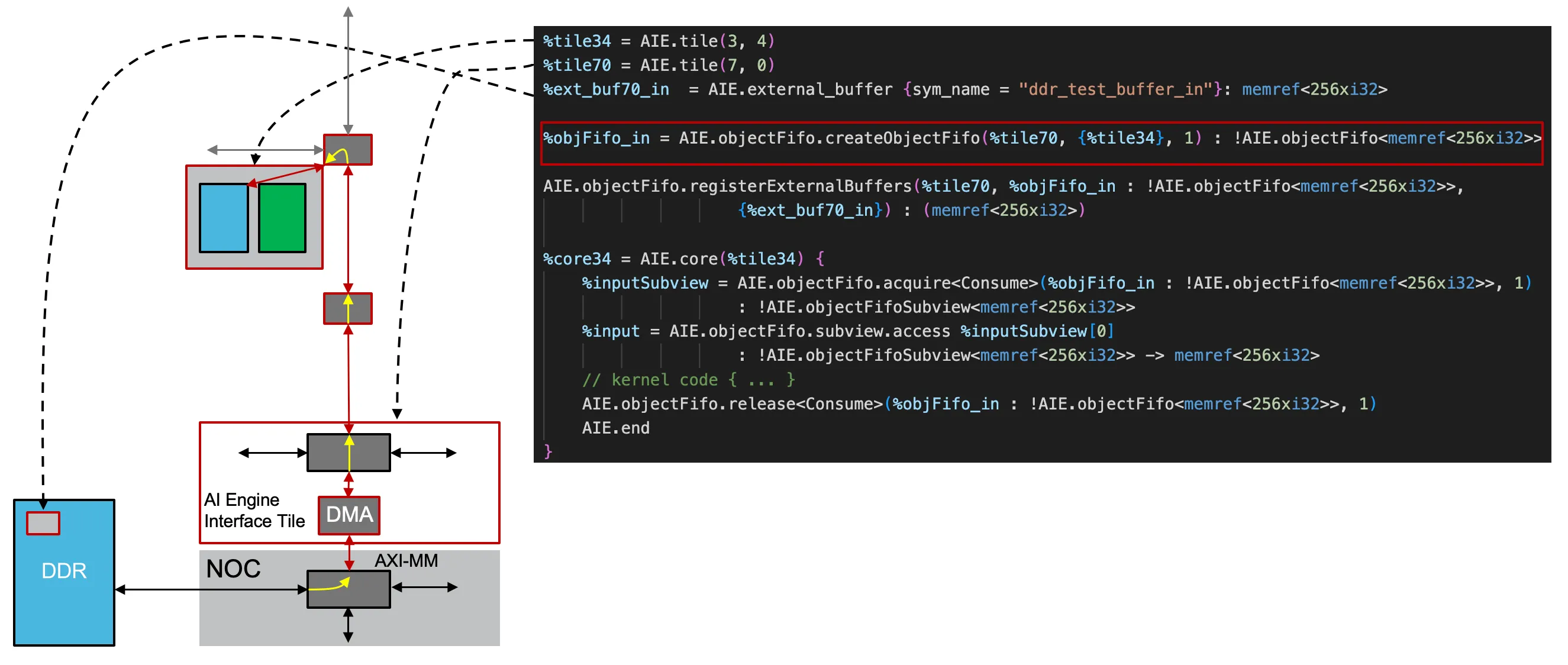
前面我们讲过,通过 objectFIFO 可以从高层次声明 Tile DMA 中的 DM 分配、同步等行为,同样的,Shim DMAs 也可以通过 objectFIFO 来简化其行为。不过这里我们需要引入一个新的 MLIR Dialect 来描述这一行为:用 aie.objectfifo.createObjectFIFO 来创建一个 从 AIE Tile 到 Shim DMA 的 objectFIFO:
|
|
NoC 片上网络
目前的 MLIR-AIE 的 NoC 配置应该只对 DDR 控制器进行了抽象,而像 PL 中的 BRAM 控制器等设备还未实现。
主机 DDR 的虚拟地址转换
由于 Shim DMAs 会与 外部 buffer (这里是 DDR 控制器)进行交互,因此需要在主机端对 DDR 的虚拟地址进行转换。而 Tile DMAs 是在运行时通过 mlir_aie_configure_dmas() 进行配置,因此无需手动配置。
在 Host 端,我们通过 MLIR-AIE 工具自动生成的主机端代码 aie.mlir.prj/aie_inc.cpp 中的一系列 API 进行控制:
|
|
其中,mlir_aie_mem_alloc()用于在物理 DDR 中申请一片内存空间并返回虚拟地址指针,mlir_aie_external_set_addr_<buffer_name>()用于将虚拟地址传递给 MLIR 中声明的外部 buffer,buffer_name 是在 MLIR 中声明的外部 buffer 的 sym_name 符号名称。最后,mlir_aie_configure_shimdma_<shim_dma_col>()用于配置 shim_dma 的行为。
此外,主机端准备好 DDR 的输入数据、准备好从 DDR 读回数据时,还需对运行时的 Shim DMAs 进行时序同步的控制:
|
|
sym_name 是在 MLIR 中声明的外部 buffer 的 sym_name 符号名称,参数 1 和 0 分别表示锁的值,而 100 表示超时时间(ms)。
6. 通过 Packet 通信
前文已经介绍了利用 Tile DMAs 进行相邻 AIE Tile 间的通信、通过 AXI4-Switch 进行不相邻 Tile 间的通信、通过 Shim DMAs 与 DDR 进行通信等方式,但它们的共同点是设计时便决定了数据的路由路径,而实际应用中可能存在需要动态改变路由路径的情况,这就需要用到 AIE 的包交换模式(AXI4-Switch 的另一种工作模式)。
Packet 包
Packet 是包交换模式下的基本数据单位。一个包由 <Packet Header,Body Data,TLAST 结束符> 构成,其详细说明见 UG1079/Packet-Stream-Operations。基本工作原理为:Packets 将在由 AXI4-Swtiches 构成的网络中路由,每个 Switch 内部维护了一张最大为 32 (5 bits)个目的地查找表,用于存储目的地 ID 和下一跳的 Tile 位置(Channel 方向和 Channel ID);当 Packet 被路由到目的 Switch 时,该 Switch 会卸载 Packet 的 Packet Header(32bits),将 Body Data 通过 S2MM 传送给 Tile DMA,并以 TLAST 结束符来标记当前 Packet 的结束。
Packet Flow
当 AXI4-Switch 工作于包交换模式时,Flow 的声明方式将变为 Packet Flow,即使用 aie.packet_flow 操作符来替代电路交换模式下的 aie.flow。其声明原型如下:
|
|
类似于 aie.flow 该操作符的参数取值如下:
| Bundle | Channels (In) | Channels (Out) |
|---|---|---|
| DMA | 2 | 2 |
| Core | 2 | 2 |
| West | 4 | 4 |
| East | 4 | 4 |
| North | 4 | 6 |
| South | 6 | 4 |
| Trace | 1 | 0 |
假如当前有个包的目的地 ID = 13,并且由 tile(1, 4) 的 DMA 0-channel 发出,路由至 tile(3, 4) 的 DMA 1-channel,那么其声明方式如下:
|
|
同时,与该 Switch 同 Tile 下的 DMA 也需使用新的 BD 描述符 aie.dma_bd_packet 来替代 aie.dma_bd,用于指定其发送包时的 ID 和包类型。其声明原型如下:
|
|
与上面声明的 Packet Flow 一致,其本地的 DMA 也需指定数据包的类型和 ID:
|
|
显然,包交换模式与电路交换模式的显著区别,或者说优势,在于包交换模式可以复用相同的 AXI4-Switch 连接路径,通过在路径中识别 Packet ID 来实现数据包的正确路由,而无需像电路交换一样,所有的数据路由必须设置为静态的、独立的连接路径。
另外,通过 Packet Flow 可以实现 一对多、多对一 的通信模型,其方案和设计流程与 UG1079/Packet Split and Merge Connections 类似,这里不再赘述。
7. 通过 Broadcast 通信
前面介绍的通信方式都是一对一的通信模型,而 AIE 还支持一对多的广播通信模型。其实现方式是通过 aie.broadcast 来声明一个广播源和多个广播目的地。本节主要介绍 MLIR-AIE 抽象出的两种广播操作:基于电路交换的广播(利用 ObjectFIFO 抽象)和基于包交换的广播(利用 Package)。
利用 ObjectFIFO 进行广播
在一对多的通信模型中,可通过创建 单生产者、多消费者 的 ObjectFIFO 抽象实现广播。这里无需考虑该 ObjectFIFO 是否共享某 Tile 的 DM,当 ObjectFIFO 用于广播时,tile DMAs 和 AXI4-Switches 都将被用于广播链路的实现,而其中的 AXI4-Switch 本身具备 反压机制,保证了广播途中数据的可靠性。下图是一个包含利用 ObjectFIFO 进行广播的示例和 MLIR-AIE 代码:
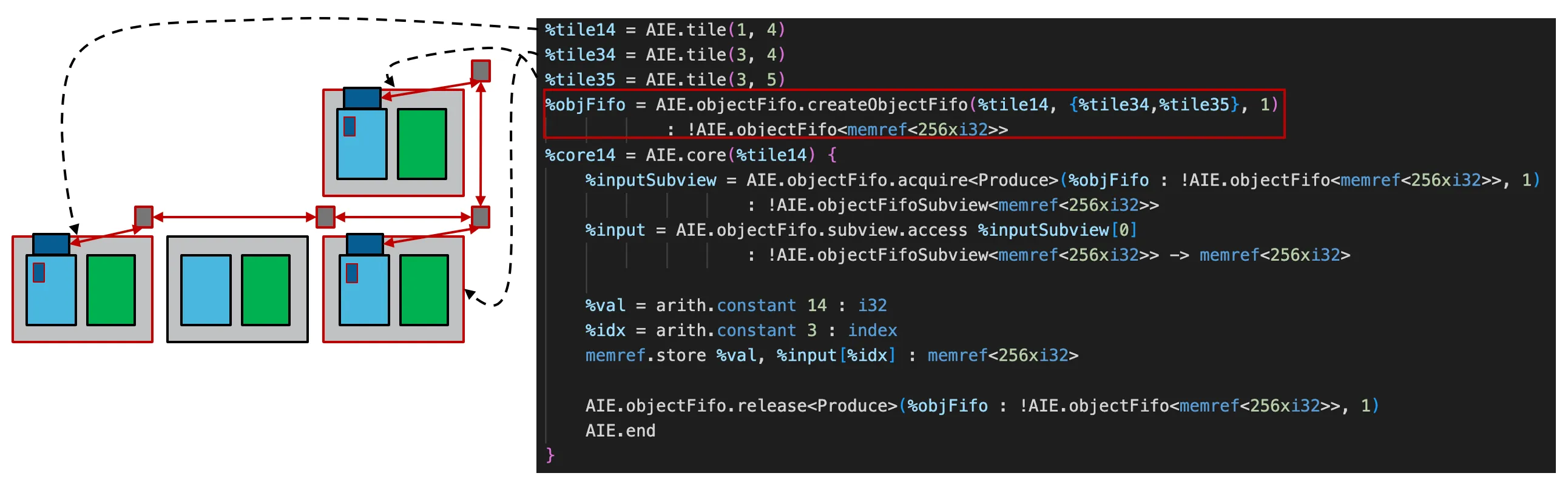
上图演示了将 Tile DMAs 作为广播源的情况,实际上还可以通过 Shim DMAs 将 DDR 的数据作为广播源,其通信模型与上图类似。
利用电路交换进行广播
这里直接复用之前的 aie.flow 操作,只需保证相同的广播源,不同的目的地即可:
|
|
注意:利用电路交换进行广播时,如果任何一个目的地的 input-channel 产生了反压,那么整个广播将被阻塞。
利用包交换进行广播
利用 Packet 包交换模式后,可以支持一对多和多对一的广播模型。由于数据流都是以包作为单位的,那么由包组成的数量流将以 Round-Robin 的方式复用 AXI4-Switches 构成的连接路径。下面是一段 1:2 的广播示例:
|
|
其中 AIEX 是 MLIR-AIE 中抽象出的属于实验阶段的 Dialect,对应有一套单独的 Passes。在使用 AIEX.broadcast_packet 时,需指定广播源的 Tile 和 Bundle:Channel,AIEX.bp_id 用于指定目的地的 Packet ID,AIEX.bp_dest 用于指定目的地的 Tile 和 Bundle:Channel。
|
|
当目的地只有一个时,比如上面这段代码,它也可以退化为使用 Packet Flow 的方式来实现:
|
|
利用 switchbox 进行广播
这部分应该是整个 MLIR-AIE 抽象出的 Dialects 中最复杂的部分(其实只是官方文档写的不友好),它将从更细粒度的 switchbox 抽象对包交换模式下的广播通信展开介绍。在第 4 节中我们简单描述了 aie.switchbox 基本使用(主要是通过 aie.connect 来连接不同的 Bundle 和 Channels),而在包交换模式下,aie.switchbox 抽象中的 aie.amsel,aie.masterset 、aie.packet_rules 和 aie.rule 等操作将被用于从更底层的角度(输入仲裁、输出选择、模式匹配三方面)来实现包交换模式下的广播通信。
aie.packet_rules
首先,aie.packet_rules(Buddle:Channel) 这一操作用于描述 Buddle:Channel 这一输入的数据流规则,具体通过其内部的 aie.rule 来实现。aie.rule 的声明原型如下:
|
|
其中,mask 是一个 5-bit 的位掩码(因为 packet-id 最多 32 个),用于匹配 value 的模式。而 value 描述了 packet-id 的值模式。当从 Buddle:Channel 输入的数据包 Header 中的 ID 在位掩码下的值与 value 相同时,则该数据包将被交由 aie.amsel 仲裁选择器进行路由。
aie.amsel
aie.amsel 抽象的对象是 AXI4-Switch 中的 arbiter 仲裁器和 master select 主选择器,其语法规则如下:
|
|
其中,arbiter 为输入仲裁,取值为 0-5;master select 为输出选择,取值为 0-3。仲裁器负责对多输入场景下的竞争仲裁,绝对 “谁先谁后” 的问题,默认在多输入场景下将使用轮询策略,单输入时直接放行。
它们为啥是 6 和 4 我没懂。
aie.masterset
最后,aie.masterset 用于结合给定的仲裁器,描述 Buddle:Channel 的输出选择,其声明原型如下:
|
|
以下是 Master 选择器的 Buddles:
| Bundle | Channels (Out) |
|---|---|
| DMA | 2 |
| Core | 2 |
| West | 4 |
| East | 4 |
| North | 6 |
| South | 4 |
上面说了一大堆,是不是很抽象?下面我们通过 2 个例子来形象说明这个 switchbox 是咋通过包交换进行广播的。
例 1:单输入 广播至 多输出
- 从 Tile(1,4) 的 DMA0 输入包
ID=0x0D的数据。 - 需要广播到 East:0 和 North:0 两个端口。
|
|
上面这段 IR 描述了 tile(1, 4) 负责从DMA:0输入,广播到East:0 和 North:0 两个 channels 的过程。
首先,当输入tile(1,4) 的数据包的header中,pktid 满足掩码条件 (0x1F, 0x0D)时,该数据包将交由仲裁器 amsel0 决定数据的广播走向,而仲裁器 amsel0 负责的数据输入只有一个,会全部放行;然后 masterset 将选择将数据复制两份,分别从该 tile 的 East:0 和 North:0 两个端口输出。
例2:多输入 竞争仲裁
|
|
- 输入竞争:
West:0和South:0同时发送数据包到amsel1。 - 仲裁调度:
- 仲裁器1采用轮询策略(默认),依次选择输入源。
- 第一周期:选择
West:0的包ID=0x0A。 - 第二周期:选择
South:0的包ID=0x0B。
- 输出路由:数据通过主选择 0 发送到
Core:0端口。
8. 通过 Cascade 通信
这个没啥好讲的,主要是考虑奇偶行 DM 共享的方向性从而推断级联的方向,以下是级联操作的声明原型:
|
|
下面是一个级联的示例:
|
|
9. 含外部函数的单核编译与仿真
尽管 MLIR 能够兼容如 arith 和 memref 这些 dialects,使其最终同样能够生成 AIE 的内核代码,但 MLIR-AIE 的这部分开源工作并不成熟,对于可部署的实际应用场景,仍然依赖于手动实现的 AIE 内核 C++ 代码作为 MLIR 的外部函数调用。本节就是针对这种情况简述如何在 MLIR-AIE 中调用外部函数编译好的可执行文件,并使其在 Module 中被正常引用。
MLIR 的外部函数语法
这里主要用到 MLIR 的两个操作符:func.func 和 func.call。
func.func
|
|
这段 MLIR 对应的 C++ 代码为:
|
|
func.func 声明了一个私有的外部函数,其函数签名 extern_kernel_func(%b: memref<256xi32>) -> () 与 C++ 保持一致。函数名用 @ 进行指定,其参数为 memref<256xi32> 类型的 buffer。对于 extern_kernel_func 在 C++ 中的指针参数,在 MLIR 中将以 裸指针 进行表示:
| MLIR type | C++ type |
|---|---|
| i32 | int32_t |
| f32 | float |
| Memref | C++ pointer |
| index | int64_t |
注意:在 MLIR 中,C++ 中的函数重载是不支持的。
对于 C++ 中的
func.call
|
|
在 MLIR 中, func.call 用于调用该外部函数。并且将 %buf 作为参数传入。
link_with
在 AIE.core 中使用 link_with 来指定外部函数所在 C++ 文件编译后的可执行文件 kernel.o,该文件将与 MLIR 生成的可执行文件进行链接。
单核编译与仿真
这一步是把外部函数(含 AIE_API)编译得到可执行文件,并且是直接调用 Vitis 中的编译器工具 xchesscc。
** 编译**
提供外部函数所在的内核文件 kernel.h,以及仿真用到的测试文件 test.cc 和项目文件 test.prx,然后调用 xchessmk 进行编译:
|
|
test.prx 的内容如下:
|
|
执行编译命令:
|
|
编译完成后会生成 work目录。
仿真
这里应该是直接调用的 aiesimulator 的底层工具 xca_udm_dbg,其命令行参数如下:
|
|
其中,-P 用于指定 aie 工具库文件夹,-t 用于指定仿真脚本 sim.tcl:
|
|
10. MLIR-AIE 的命令与工具集
MLIR-AIE Dialect 构建了一系列命令工具,用于将 MLIR-AIE 编写的操作编译和转换为其他 IR,并生成可在板上运行的 AIE 程序 ELF 文件和主机可执行文件。构建 MLIR-AIE 项目后,主要提供两个输出工具:aie-translate 和 aie-opt,它们用于将 MLIR-AIE 转换为其他 IR。这些工具随后被便捷的 Python 工具 aiecc.py 使用,将 MLIR-AIE 编写的操作编译为 ELF/主机可执行文件。
aiecc.py
我们使用 aiecc.py 将 MLIR-AIE 编写的代码(例如 aie.mlir)编译为 ELF/主机可执行文件(例如 core_*.elf、test.exe)的基本方式如下:
|
|
该命令将 MLIR-AIE 的源文件(如 aie.mlir)编译为 AI Engine 程序 ELF 文件,并生成主机 API 文件 aie.mlir.prj/aie_inc.cpp,该文件可用于配置 AIE。此外,如果提供了主机源文件(例如 test.cpp),aiecc.py 会将其编译为主机可执行文件(如 tutorial-1.exe)。AIE 模块的 ELF 文件会自动为每个需要编程的 AIE 模块生成。此外,我们通常会传递 <runtime lib>/test_library.cpp 的引用,因为它包含常用的测试函数。
aiecc.py -h 支持的参数:
| 可选参数 | 描述 |
|---|---|
--sysroot sysroot |
用于交叉编译的 sysroot |
-v |
跟踪执行的命令 |
--vectorize |
启用 MLIR 向量化 |
--xbridge |
使用 xbridge 进行链接(默认) |
--xchesscc |
使用 xchesscc 进行编译(默认) |
--compile |
启用 AIE 代码编译(默认) |
--no-compile |
禁用 AIE 代码编译 |
--host-target HOST_TARGET |
主机程序的目标架构(例如 vck190 使用 aarch64-linux-gnu) |
--compile-host |
启用主机程序编译(默认) |
--no-compile-host |
禁用主机程序编译 |
--link |
启用 AIE 代码链接(默认) |
--no-link |
禁用 AIE 代码链接 |
-j NTHREADS |
使用机器的最大线程数进行编译(默认为 1)。参数为零表示使用机器上的最大线程数。 |
--profile |
分析命令以找到最耗时的执行部分。 |
--unified |
在单一进程中一起编译所有核心(默认) |
--no-unified |
在独立进程中分别编译核心 |
-n |
禁用实际执行任何命令 |
aie-opt
用于在 MLIR-AIE 定义的范围内将源代码从一个表示形式转换或优化为另一个表示形式。这主要通过命令行选项控制,添加多个选项可以让工具执行多次转换/优化。选项的完整描述可以在这里找到,但一些示例选项包括从逻辑描述转换为更物理的描述,例如在教程 4 中的 stream 和 switchbox 之间的转换。
aie-translate
此工具更倾向于将描述完全转换为另一种格式。比如,生成辅助文件 .bcf 和 .ldscript 。
aiecc.py 的流程
这里不详细讲解 aiecc.py 的源代码,而是描述 aiecc.py 对 aie-translate 和 aie-opt 的一些主要调用,并展示使用的参数以提供对其功能的了解。
aiecc.py 的主要流程如下:
- 1、 第 1 组优化
- 2、 翻译文件以计算设计中的 AI Engine 核心数量
- 3、 第二组优化
- 4、 翻译为 LLVM-IR
- 5、 编译单个核心(例如
xchesscc_wrapper) - 6、 处理主机代码的 ARM 交叉编译
- 7、 循环遍历核心
- 第一组核心优化
- 第二组核心优化
- 翻译生成
.bcf或.ldscript - 编译核心(例如
xchesscc_wrapper)
1. 第一组优化
|
|
2. 计算设计中的 AIE 核心数量
|
|
3. 第二组优化
|
|
4. 翻译为 LLVM-IR
|
|
5. 编译单个核心(xchesscc_wrapper)
|
|
6. ARM 主机代码的 交叉编译
此部分执行交叉编译,包括调用具有特定目标的 clang。然而,这里会调用 aie-opt 和 aie-translate 来生成 aie.mlir.prj/aie_inc.cpp 文件。
|
|
|
|
7. 第一组核心优化
|
|
8. 第二组核心优化
|
|
9. 翻译生成 .bcf 或 .ldscript
|
|
或
|
|
10. 编译核心(xchesscc_wrapper)
此部分调用 xchesscc_wrapper 来编译最终的 core*.elf。
|
|
 支付宝
支付宝
 微信
微信
