 Albresky's Blog
Albresky's Blog[CVPR 2023] STMixer: 一种单阶段的稀疏动作检测器
CVPR 2023 动作检测与识别论文阅读笔记
STMixer: A One-Stage Sparse Action Detector
一、前置知识
在介绍本文前,我们先来了解一下文章中多处提及的 ROI Align。
1.1 什么是 RoI
RoI 即 Region of Interest,是原始图像中的“目标”区域(“感兴趣”的区域),将RPNs(Rigion Proposal Networks)输出的region proposals映射到feature maps中,此时feature maps中的region proposals就称为RoI,比如下图中的4个矩形框框出的区域即为ROI。
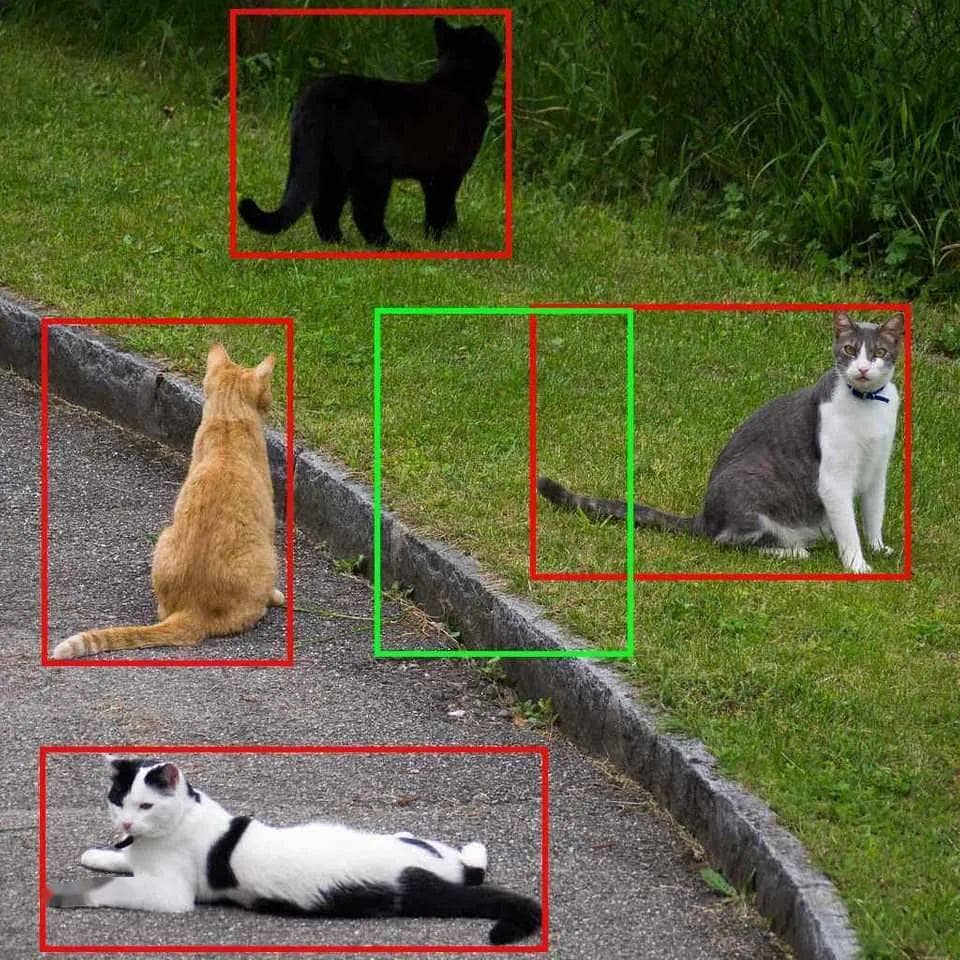
然而,在将region proposals映射到feature maps时,可能会时会使部分regions 的边框与feature maps的cells不对齐,此时就需要对这些未对齐的边框位置进行约减,这个过程称其为量化(quantization)。
显然,在量化过程中会导致原来部分落在cells中的不完整区域被丢弃或扩充,从而形成量化损失(quantization loss),如下图所示。
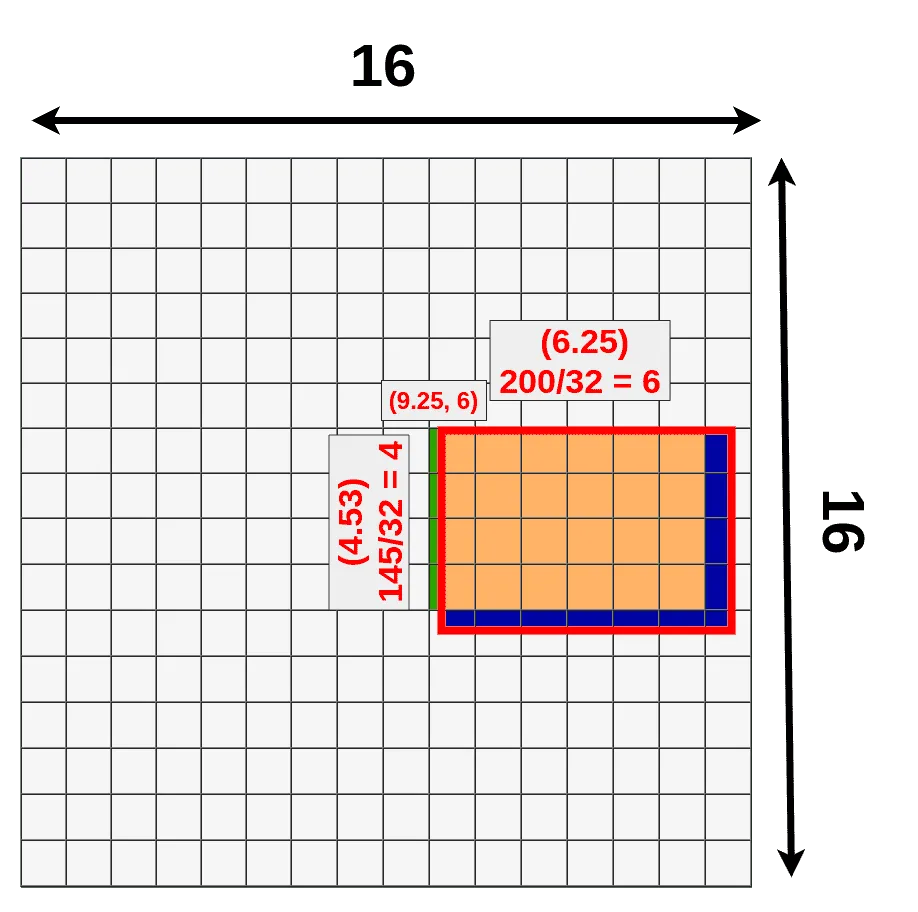
- 上图中,蓝色部分即为量化时丢失的区域,而绿色区域即为量化时填充cells后获得的原来RoI外部的区域。
尽管量化损失造成了部分信息丢失,这却并不影响对RoI的池化操作,毕竟此时feature maps中的RoI都已完整占据在cells中。
1.2 RoI Pooling
回到开始,为什么要对RoI进行池化操作呢?

在 Fast R-CNN 中,backbone输出的feature maps中的RoI是要进入全连接层(下图中的FCs)进行分类的,而Fast R-CNN的全连接层的大小固定,feature maps中的RoI并非都尺寸相同,因此这时需要对这些RoI进行池化操作,以得到尺寸相同的RoI。
如下图所示,比如feature map中的一个RoI尺寸为$4 \times 6$,且目标是将其池化到$3 \times 3$的尺寸。
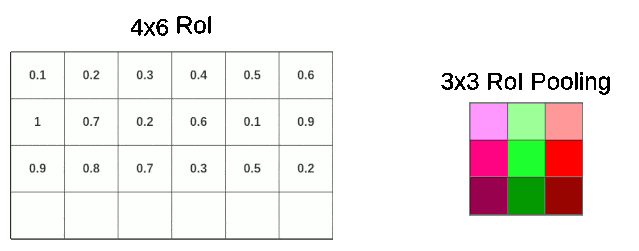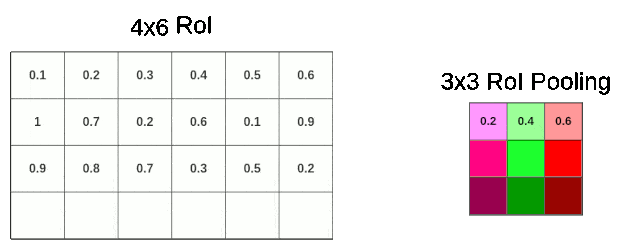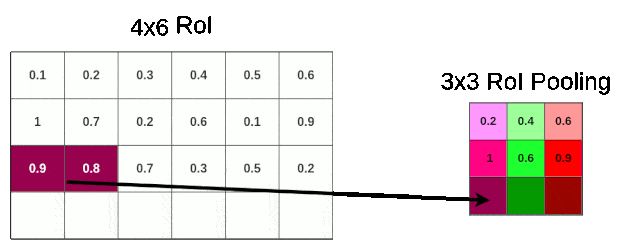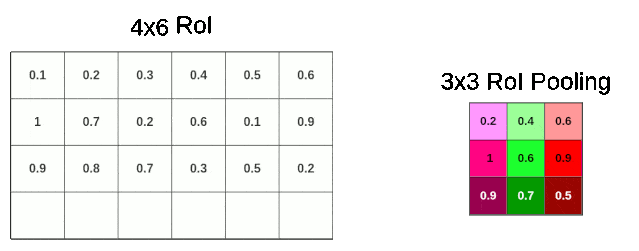
我们可以根据RoI的长度除以3得到采样窗口的长度,RoIl的宽度除以3得到采样窗口的宽度。但显然RoI的宽度4是不能被3整除的,此时RoI Pooling就需要进行一次量化操作,将多余的一行cells丢弃,从而获得一个$2 \times 1$的采样窗口,进而进行池化(这里演示的是最大池化)。
对于feature maps中所有的RoI的所有层进行RoI Pooling,便可以得到若干个如下$3\times3\times512$的矩阵,这些矩阵便是 Fast R-CNN 中全连接层的输入了。

1.3 RoI Align
在 RoI Pooling 中,我们为了进行池化操作,在RoI Pooling Layer前进行了一次量化,在RoI Pooling过程中又进行了一次量化。尽管量化操作使得RoI Pooling得以正常进行,但对于有若干层的若干个RoI来说,量化造成的信息损失是不可忽略的。因此,便引入了 RoI Align 来解决这一问题。

对于特征图上的RoI,在RoI Align之前前无需对其进行量化。这里我们假设同样输出$3\times3$的矩阵,那么我们直接将原始RoI等分成$3\times3$个boxes,即每个部分的长=$6.25\div3$=$2.08$,宽=$4.53\div3=1.51$,而每个box内使用双线性插值法进行采样,对于每个box内的采样点进行最大池化,便得到了该RoI的RolAlign结果矩阵如下图所示。
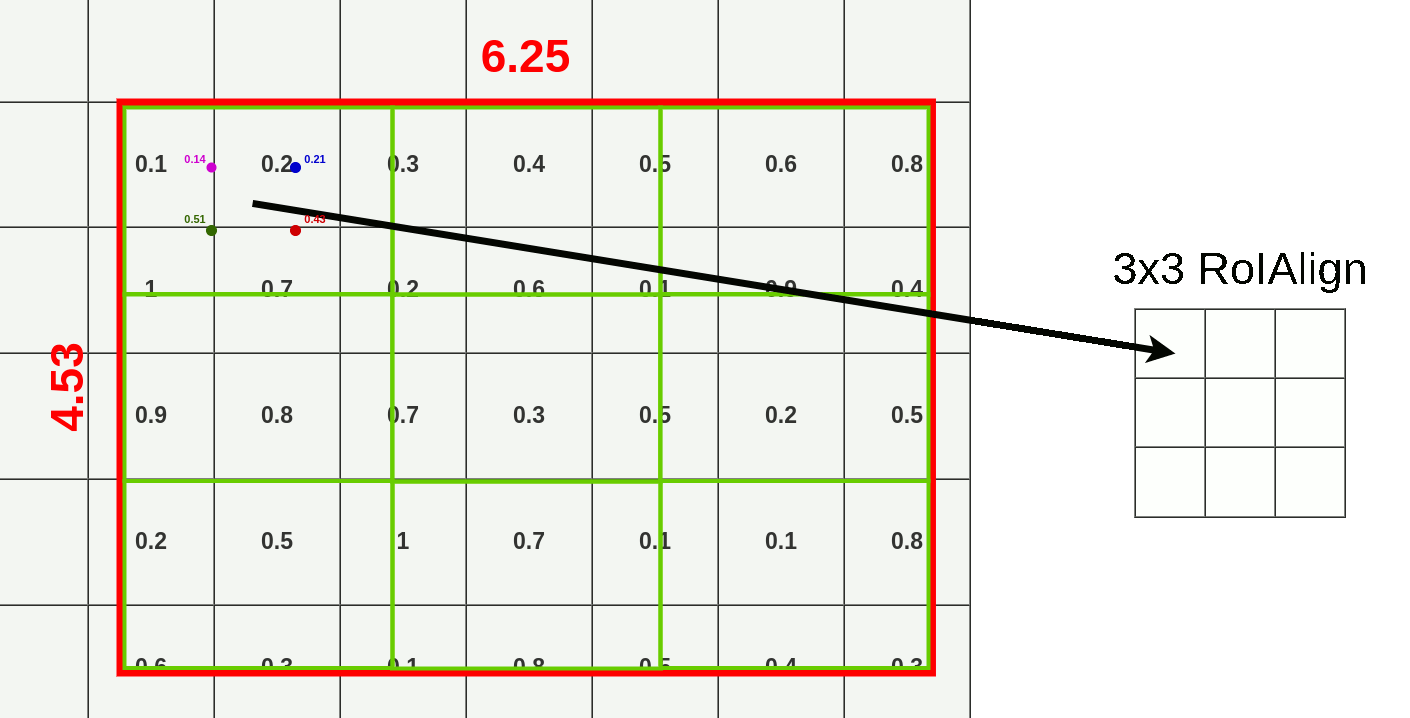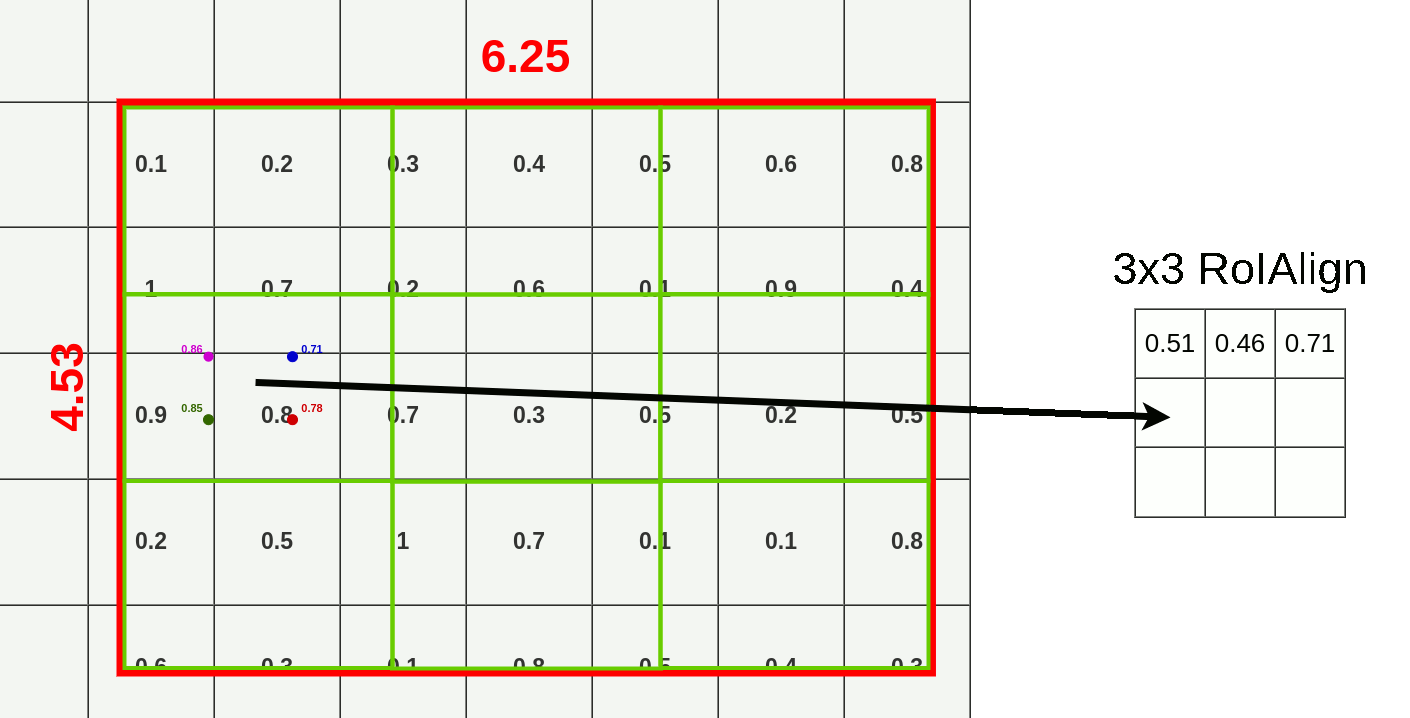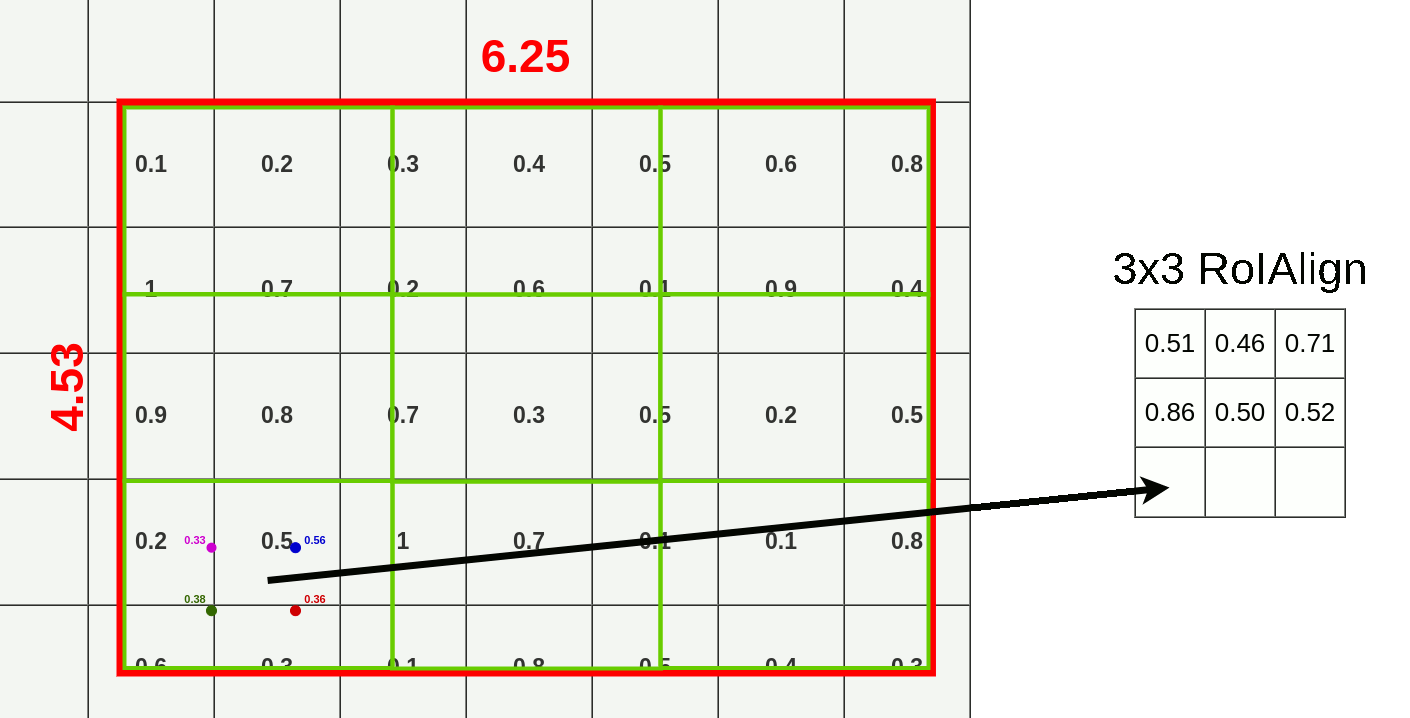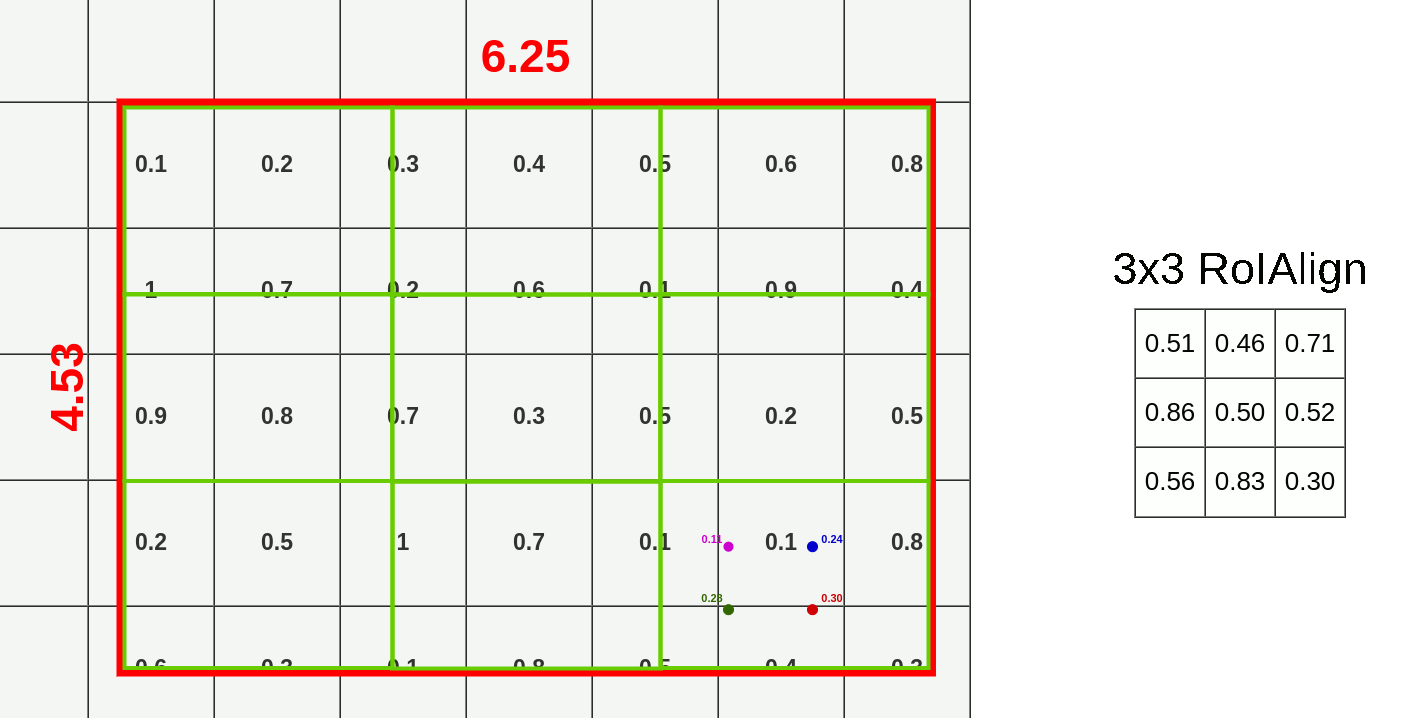
观察下图,相较RolPooling,RolAlign的数据源显然更多。
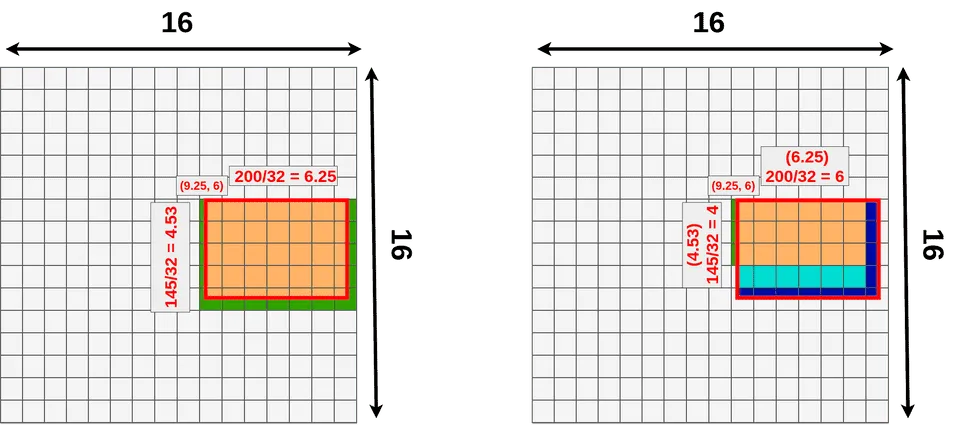
- 绿色:用于池化的额外数据
- 浅/深蓝色:池化时丢失的数据
1.4 RoI Warp
RoI Warp同样是RoIPooling的一个变种,它与RoI Align的区别甚小,主要在于它对RoIPooling的第一次量化改成了可以指定的尺寸大小,而不是RoI Align中的不采取第一次量化。
观察下图可以发现,RoI Warp根据指定尺寸的不同,可能会产生数据丢失。

二、文章概要
2.1 主要贡献
- 提出了一种单阶段的稀疏动作检测器,称为 STMixer,能够以端到端的方式进行训练,同时具有高效和准确的特性。
- 主要进行了两个核心设计
- 自适应特征采样模块
- 双分支特征混合模块
- 在三个主流数据集上获得了SOTA的表现
三、主要方法
STMixer 的整体架构如下图所示。
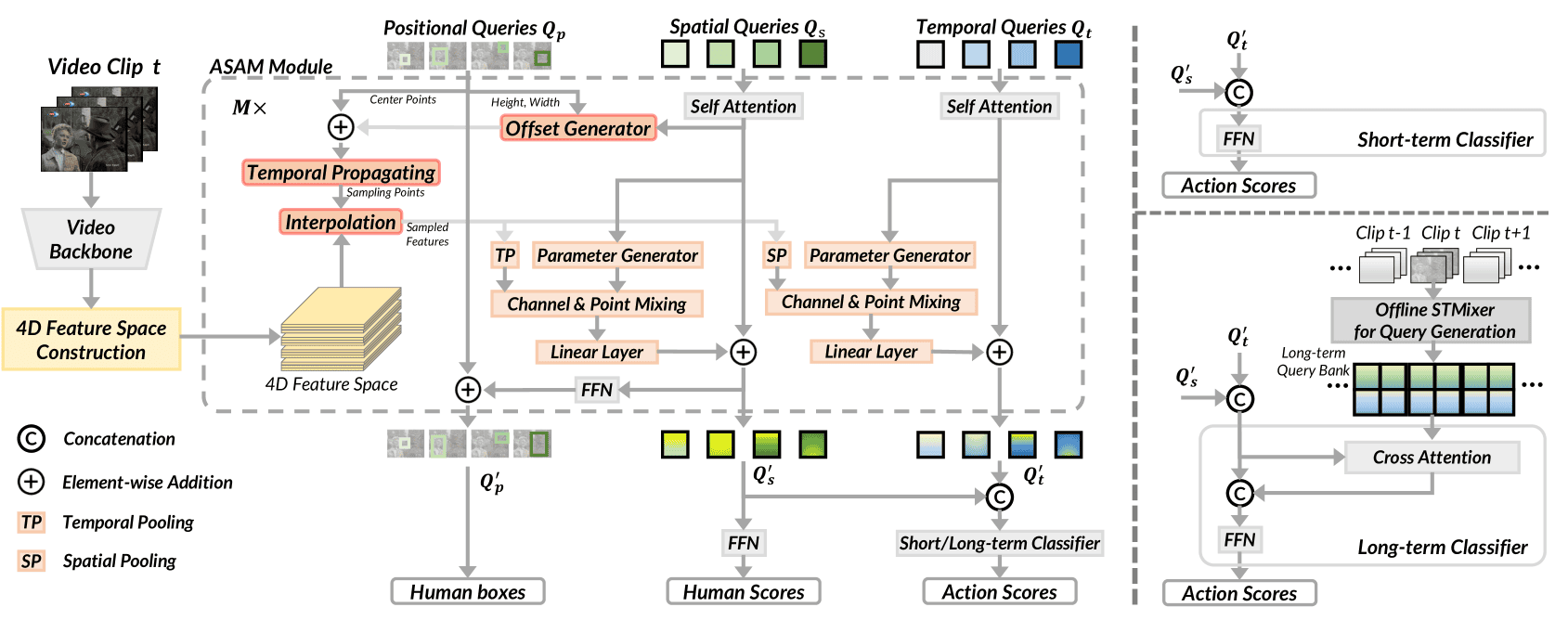
STMixer 主要包含三个部分:
- 用作特征提取的一个视频主干网络
- 一个特征空间构建模块(
4D Feature Space Construction) - 一个稀疏动作检测器(
Sparse Action Detector)- 由M个适应性采样混合模块(
Adaptive sampling and adaptive mixing, ASAM)构成
- 由M个适应性采样混合模块(
将输入视频片段(clip)的中间帧作为关键帧,将其输入到主干网络中,得到一个特征图$F$。然后将其输入到特征空间构建模块中,得到一个$4D$的特征空间$F_{4D}$。最后将其输入到稀疏动作检测器 ASAM 中,最终输出视频中的人体边框、人体得分,以及动作得分。
其中,ASAM模块由$F_{4D}$、$Q_p$、$Q_s$、$Q_t$作为输入,且这些queries在ASAM的迭代过程中会不断被更新。
此外,STMixer 还分别用了长、短期的分类器来输出每个预测动作的得分。其中长期的分类器是指利用预训练好的 STMixer 对视频片段进行长期的动作类别分类进行打分。
3.1 4D 特征空间构建模块
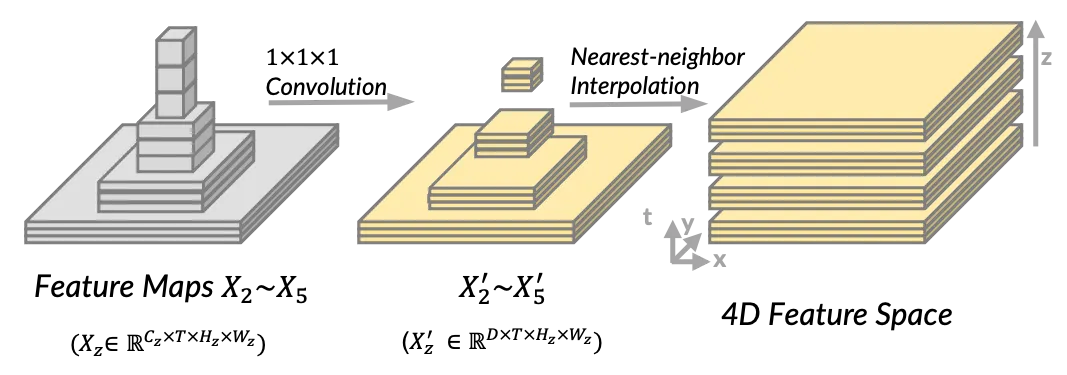
该模块主要通过分层视频骨干网络和普通ViT骨干网络来构建4D特征空间。对于分层视频骨干网络,它通过简单的横向卷积和最近邻插值来构建4D特征空间。对于普通ViT骨干网络,它通过在ViT骨干网络的最后一个特征图上使用不同步长的卷积来构建4D特征空间。
3.1.1 分层视频骨干网络
该模块中,定义了$X_z\in R^{{C_z}\times T \times{H_z}\times{W_z}}$来表示分层主干网络的第 $z$ 个卷积阶段的特征图,$z$ 表示卷积阶段的索引,可以理解为卷积前后特征图的缩放比例(此时特征图以 $2^z$ 作为下采样率)。在某个缩放比例 $z$ 下,$C_z$ 表示通道数, $T$ 为时间维度,$H_z$ 和 $W_z$ 分别为特征图的高和宽。
通过$1\times1$的卷积核,将输入的特征图维度转变到相同的通道数$D$,得到${X_z}^{’}\in R^{D\times T \times{H_z}\times{W_z}}$,然后通过 最近邻插值 将转变通道数后的特征图的尺寸转变到 ${H_2}\times{W_2}$,并且将其与$x$、$y$坐标对齐,最后得到一个转变结束的特征图 ${X_z}^{4D}\in R^{D\times T \times{H_2}\times{W_2}}$。
3.1.2 普通ViT骨干网络
为了和普通的ViT保持一致,该文将$2^4$的下采样率输出的特征图作为输入,以${ \frac{1}{4}, \frac{1}{2},1,2}$作为步长将${X_z}$的通道数变为$D$,最后再将特征图的尺寸转变到 ${H_2}\times{W_2}$。
3.2 Query 的定义
STMixer 参照 Sparse R-CNN 定义queries。与其不同的是,STMixer 将动作query分解成了两部分:$Q_s \in \mathbb{R}^{N \times D}$和$Q_t \in \mathbb{R}^{N \times D}$,分别用于对特征空间中的空间维度和时间维度进行采样。其中,$N$表示queries的数量,$D$表示每个query的维度。
此外,STMixer 进一步定义了$Q_p \in \mathbb{R}^{N \times 4}$。对于每一个$Q_p^n$($n$表示query index),其表示了一个proposal box向量 $(x^n, y^n, z^n, r^n)$,其中$x^n$和$y^n$分别代表框中心的横纵坐标$x$,$y$,而$z^n$代表框的尺寸的对数值,$r^n$代表框的长宽比。在对$Q^p$进行初始化时,每一个box vector都将视为一个关键帧。
3.3 自适应的时空特征采样
与通过预计算得到候选框的方法不同,STMixer 通过空间$Q_s$,在$4D$特征空间中对动作进行了采样。
具体而言,将候选框的中心坐标$(x^n, y^n, z^n)$作为一个参考点,对于一个给定的$Q_s$和与其相关的$Q_p^n$,对$P_{in}$组$x$、$y$、$z$维度的偏移量做关于$Q_s^n$的线性回归:
$$ \begin{aligned} {(\Delta x^n_i,\Delta y^n_i,\Delta z^n_i)} &= Linear(Q_s^n), \ where i \in \mathbb{Z}; and; i &\in [1, P_{in}] \end{aligned} $$
然后将得到的偏移量与参考点相加,得到$P_{in}$组空间特征点:
$$ \begin{aligned} \begin{cases} \hat{x}^n_i &= x^n + \Delta x^n_i \cdot 2^{z^n- r^n} , \ \hat{y}^n_i &= y^n + \Delta y^n_i \cdot 2^{z^n-r^n} , \ \hat{z}^n_i &= z^n + \Delta z^n_i \end{cases} \end{aligned} $$
最后,将这些采样点沿时间维度进行传播,即可获得$T\times P_{in}$个采样点,然后将其输入到$4D$特征空间中,得到$T\times P_{in}$个采样点的特征向量,最后再将其输入到稀疏动作检测器中。
3.4 自适应双分支特征混合
由于双分支特征混合模块在时间和空间两个维度上是完全一致的,故这里仅对空间上的特征混合进行介绍。
上一节的特征采样结束后,本模块则通过池化操作将采样后的特征向量分解到时、空两个维度,然后再对其进行自适应混合。
对于一个给定的空间查询$Q_s^n \in \mathbb{R}^D$和与其关联的采样后的特征矩阵$F^n\in \mathbb{R}^{T\times P_{in}\times D}$($F^n$即上节采样过后的$Q_s^n$),首先利用一个线性层来生成特定query的通道混合权重$M_c \in \mathbb{R}^{D\times D}$,然后将其与特征矩阵$F^n$在时间维度上池化后的矩阵相乘,再进行正则化,输出通道混合后的特征$CM(F^n)$:
$$ \begin{aligned} M_c &= Linear(Q_s^n) \in \mathbb{R}^{D\times D}, \ CM(F^n) &= ReLU(LayerNorm(GAP(F^n)\times M_c)) \end{aligned} $$
其中, $GAP$表示在时间维度上的全局平均池化,$LayerNorm$表示层归一化,$ReLU$为激活函数。
在通道混合后,点混合亦是以类似的方式进行。假设$P_{out}$为空间点混合的结果矩阵,那么可以用$PCM(F^N)\in \mathbb{R}^{D\times P_{out}}$表示出空间点混合后输出的特征矩阵:
$$ \begin{aligned} M_p &= Linear(Q_s^n) \in \mathbb{R}^{P_{in}\times P_{out}}, \ PCM(F^n) &= ReLU(LayerNorm(CM(F^n)\times M_p)) \end{aligned} $$
最后,将$PCM(F^n)$变形到$D$维后加到空间查询$Q_s^n$上。$Q_t^n$的更新方式与$Q_s^n$完全对应,只不过$Q_t^n$是对空间维度进行池化。在对全局空间进行池化后,即有用于时间混合的$T$个不同时间的特征点,这些点的时间混合的结果的数量我们不妨记为$T_{out}$。
3.5 稀疏动作编码器
首先,该编码器由M个 ASAM 模块、一个用于动作预测结果打分的前馈网络(FNN),以及一个用于动作得分预测的短期或长期的分类器构成。
3.5.1 ASAM 模块(Adaptive Sampling and Adaptive Mixing Module)
在该模块中,首先对$Q_s$和$Q_t$分别进行self-attention,接着对4D特征空间进行自适应采样,并对采样后的特征进行自适应双分支混合(具体过程如上两小节所述),此时$Q_s$和$Q_t$会被混合后的特征更新成$Q_s’$和$Q_t’$;然后前馈网络FNN再利用$Q_s’$来更新$Q_p$;最后更新过后的$Q_p’$、$Q_s’$、$Q_t’$在作为下一轮ASAM模块的输入。
3.5.2 预测头的输出
如xxx图所示,从$Q_p’$解码可以得到人体框。将$Q_s’$输入到前馈网络即可输出人体预测的得分$S_H\in \mathbb{R}^{N\times 2}$,用以表示每个人体框的分类是属于人还是背景的一个置信度。此外,再利用一个短期或长期的分类器对一系列连续的$Q_s’$和$Q_t’$输出动作预测的得分$S_A\in \mathbb{R}^{N\times C}$,其中,$C$表示动作类别标签的数量。
3.5.3 长短期分类器
- 短期分类器
上述小节中所提及的短期分类器就是一个简单的FFN网络,用以输出当前查询的短期的动作预测得分。
- 长期分类器
简单而言,模型中使用的长期分类器,就是未利用长期信息的一个预训练的STMixer对一个视频的若干片段(这里不妨记片段数量为$\tau$)进行推理的过程。
将上一轮ASAM模块中每个视频片段中$k$个动作预测得分最高的一系列时空查询存储起来(这里不妨记存储的视频片段长度为$t$的查询$L_t\in \mathbb{R}^{k\times d}$,$d=2D$;记存储的长期的查询$L=[L_0,L_1,…,L_{\tau -1}]$),然后利用所有视频的$L$,从头训练一个带有长期信息的STMixer。
在长期查询的库中选取一个以视频片段$t$为中心的长度为$w$的窗口,然后将其堆叠至$\widetilde{L_t}\in \mathbb{R}^{K\times d}$:
$$ L_t=stack([L_{t-w/2},…,L_{t+w/2-1}]) $$
最后便可根据$\widetilde{L_t}$,利用cross-attention对当前的查询$S_t$进行推理:
$$ S_t’=\text{cross-attention}(S_t,\widetilde{L_t}) $$
其中,$S_t\in \mathbb{R}^{N\times d}$为ASAM模块上一轮输出的一系列时空查询,而$S_t’$则是用于动作得分预测的融合了多个通道信息的$S_t$。
四、训练
基于上述方法输出结果中的人体动作框、人体得分、动作预测得分,有损失函数如下:
$$ \begin{aligned} L_{set} &={\lambda}{cls}L{cls}+{\lambda}{L_1}L{L_1}+{\lambda}{giou}L{giou} \ L &=L_{set}+{\lambda}{act}L{act} \end{aligned} $$
其中,$L_{cls}$表示人体和背景两个类别的交叉熵损失,$L_{act}$表示动作类别的交叉熵损失。
五、实验结果
5.1 数据集
STMixer 在主流的AVA、JHMDB、UCF101-24数据集上进行训练和测试,各数据集的详细信息如下:
| 数据集 | 训练集 | 测试集 | 动作类别 | 视频数量 | 视频时长 |
|---|---|---|---|---|---|
| AVA | 211K | 57K | 80+ | 430K+ | 1.57M+ |
| JHMDB | 928 | 1.2K | 21 | 3.7K | 1.5K |
| UCF101-24 | 9.5K | 3.7K | 24 | 13.3K | 27.6K |
5.2 网络参数设置
| 参数 | 值 |
|---|---|
| $D$ | 256 |
| $N$ | 100 |
| $P_{in}$ | 32 |
| $P_{out}$ of SlowFast | 128 |
| $T_{out}$ of SlowFast | 32 |
| $P_{out}$ of CSN&ViT | 128 |
| $T_{out}$ of CSN&ViT | 16 |
| $k$ | 5 |
| $w$ | 60 |
5.3 实验结果对比
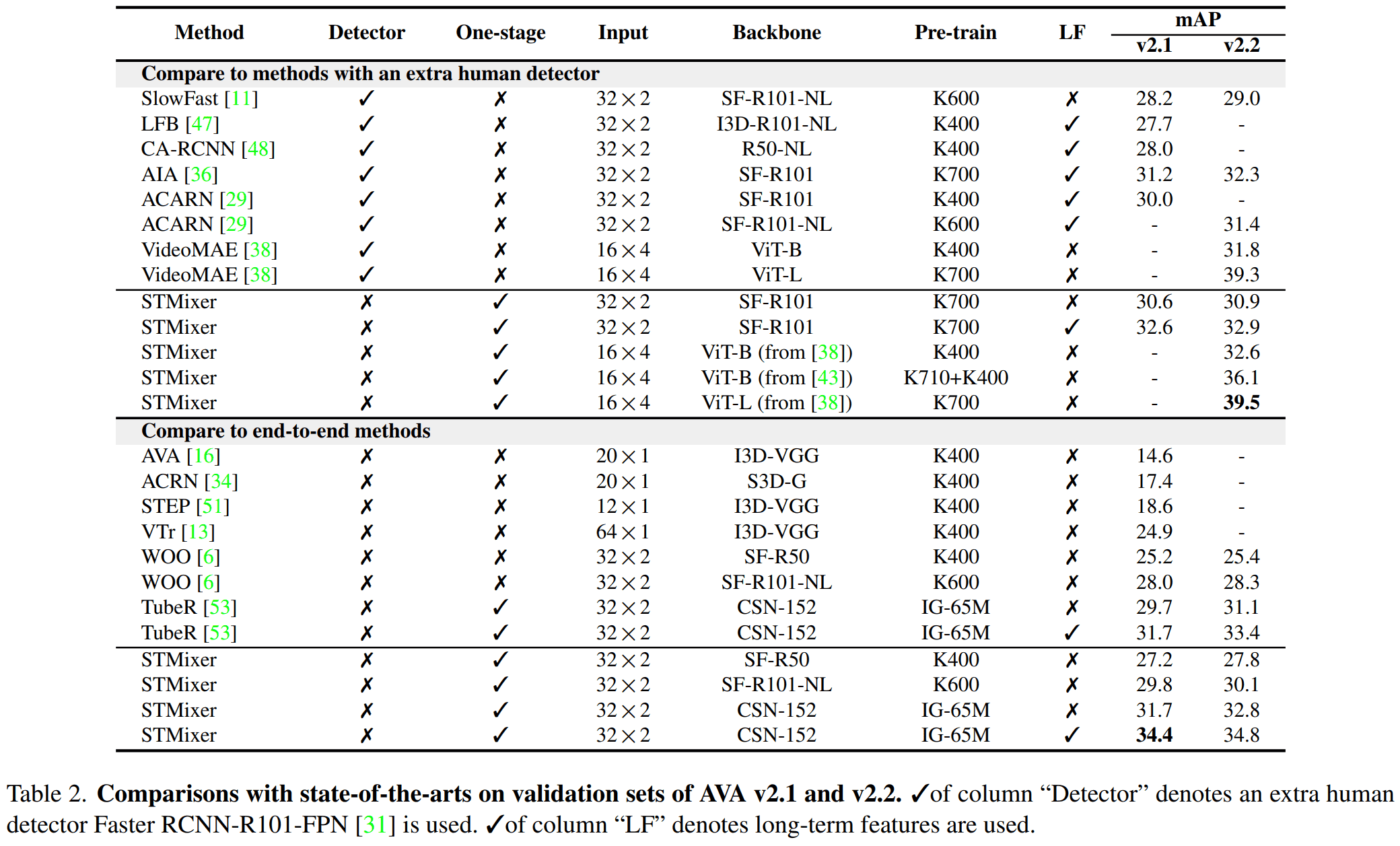
- STMixer 与 SOTA 方法在 AVA 数据集上的对比
- STMixer 与 SOTA 方法 在 JHMDB 和 UCF101-24 数据集上的对比

 支付宝
支付宝
 微信
微信
